데이터베이스에서 테이블을 생성에 있어서 가장 기본적으로 고려되는 PK(Primary Key)입니다.
이 PK의 중요성 만큼 FK(Foreign Key)는 중요시 되지 않는것 같아 PK와 더불어 FK에 대해 알아 보면서 FK의 중요성에 대해서 알아 보겠습니다.
데이터베이스의 목적은 말그대로 수 많은 데이터들을 보관 및 관리하는 것입니다.
그것도 효율적이고, 성능면에서 매우 편리하며 신속한 처리를 요하는 것입니다.
이 모든것 보다 우선시 되어야 하는 것이 데이터의 무결성입니다.
아무리 많은 데이터를 아무리 신속하게 처리한다 하더라도 데이터에 결점이 있다면 데이터는 쓸모가 없을 뿐 아니라, 데이터의 결점으로 인하여 잘못된 결과를 초래할 수도 있습니다.
이러한 이유로 데이터 무결성은 매우 중요한 부분이라 하겠습니다.
이 데이터 무결성을 보장해주기 위해서 가장 기본적으로 필요한 것이 PK와 FK입니다.
우선 PK는 테이블에서 오직 한개만 존재할 수 있으며, 이 PK는 테이블에서 데이터의 유일성을 보장해 줍니다.
PK의 구성은 B*tree Index, Unique, Not Null의 구조를 가지고 있습니다.
이러한 구조이므로 테이블에서 PK를 조건으로 조회를 하면 오로지 한개의 값만 나오거나 아니면 값이 나오지 않게 되는 것입니다.
그럼 PK와 FK는 어떠한 관계를 가지고 있는 것일까요?
예를 들어보겠습니다.
학과 테이블이 있습니다. 이 테이블에는 학과코드가 PK입니다.
그리고 학생 테이블이 있습니다. 이 테이블에는 학생번호가 PK입니다.
또한 학생은 하나의 학과에 등록이 되어야 한다는 조건이 있다면, 학생테이블에 학과코드의 테이터가 있어야 하겠지요.
그럼... 만약 학생테이블의 학과코드의 값에 학과테이블의 학과코드에 없는 값이 들어간다면 어떻게 되겠습니까?
잘못된 데이터가 들어가게 되고, 이러한 데이터를 부모를 잃어버렸다라고 합니다.
그러므로 학생테이블에 데이터를 저장 또는 수정시 학과코드 데이터는 학과테이블에 있는 학과코드가 맞는지를 확인해야 합니다.
이것을 자동하여 주는 것이 FK입니다.
그래서 FK는 PK를 대상으로만 만들 수 잇습니다.
이것은 FK가 항상 PK를 참조하게 되는데, 만에 하나 FK가 유일인덱스가 아닌 데이터를 매번 조회하게 되면 성능에 심각한 문제가 발생할 수 있으므로 이러한 문제를 미연에 방지하기 위하여 기본적인 성능을 보장하여야 하는 조건을 강제로 하기 위해 PK를 대상으로만 FK를 만들수 있게 한것입니다.
SQL Injection이란 악의적인 사용자가 보안상의 취약점을 이용하여,임의의SQL문을 주입하고 실행되게 하여 데이터베이스가 비정상적인 동작을 하도록 조작하는 행위 입니다.인젝션 공격은OWASP Top10중 첫 번째에 속해 있으며,공격이 비교적 쉬운 편이고 공격에 성공할 경우 큰 피해를 입힐 수 있는 공격입니다.
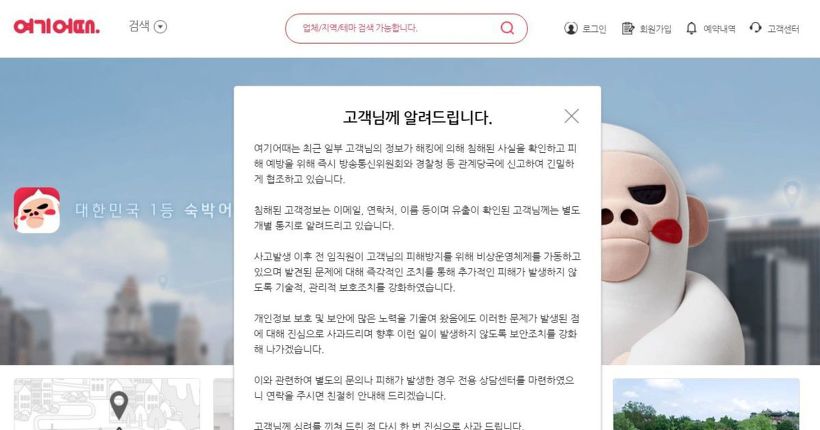
여기어때 해킹 사건
2017년3월에 일어난“여기어때”의 대규모 개인정보 유출 사건도SQL Injection으로 인해 피해가 발생하였습니다.
SQL공격 기법은 여러 가지가 있는데 논리적 에러를 이용한SQL Injection은 가장 많이 쓰이고,대중적인 공격 기법입니다.
Error based SQL Injection
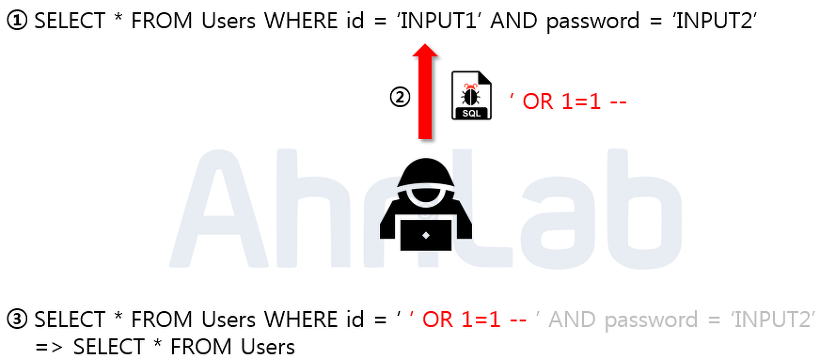
위의 사진에서 보이는 쿼리문은 일반적으로 로그인 시 많이 사용되는SQL구문입니다.해당 구문에서 입력값에 대한 검증이 없음을 확인하고,악의적인 사용자가 임의의SQL구문을 주입하였습니다.주입된 내용은‘ OR 1=1 --로WHERE절에 있는 싱글쿼터를 닫아주기 위한 싱글쿼터와OR 1=1라는 구문을 이용해WHERE절을 모두 참으로 만들고, --를 넣어줌으로 뒤의 구문을 모두 주석 처리 해주었습니다.
매우 간단한 구문이지만,결론적으로Users테이블에 있는 모든 정보를 조회하게 됨으로 써 가장 먼저 만들어진 계정으로 로그인에 성공하게 됩니다.보통은 관리자 계정을 맨 처음 만들기 때문에 관리자 계정에 로그인 할 수 있게 됩니다.관리자 계정을 탈취한 악의적인 사용자는 관리자의 권한을 이용해 또 다른2차피해를 발생 시킬 수 있게 됩니다.
Union based SQL Injection
Union명령어를 이용한SQL Injection
SQL에서Union키워드는 두 개의 쿼리문에 대한 결과를 통합해서 하나의 테이블로 보여주게 하는 키워드 입니다.정상적인 쿼리문에Union키워드를 사용하여 인젝션에 성공하면,원하는 쿼리문을 실행할 수 있게 됩니다. Union Injection을 성공하기 위해서는 두 가지의 조건이 있습니다.하나는Union하는 두 테이블의 컬럼 수가 같아야 하고,데이터 형이 같아야 합니다.
Union based SQL Injection
위의 사진에서 보이는 쿼리문은Board라는 테이블에서 게시글을 검색하는 쿼리문입니다.입력값을title과contents컬럼의 데이터랑 비교한 뒤 비슷한 글자가 있는 게시글을 출력합니다.여기서 입력값으로Union키워드와 함께 컬럼 수를 맞춰서SELECT구문을 넣어주게 되면 두 쿼리문이 합쳐서서 하나의 테이블로 보여지게 됩니다.현재 인젝션 한 구문은 사용자의id와passwd를 요청하는 쿼리문 입니다.인젝션이 성공하게 되면,사용자의 개인정보가 게시글과 함께 화면에 보여지게 됩니다.
물론 패스워드를 평문으로 데이터베이스에 저장하지는 않겠지만 인젝션이 가능하다는 점에서 이미 그 이상의 보안위험에 노출되어 있습니다.이 공격도 역시 입력값에 대한 검증이 없기 때문에 발생하게 되었습니다.
Blind SQL Injection
Boolean based SQL
Blind SQL Injection은 데이터베이스로부터 특정한 값이나 데이터를 전달받지 않고,단순히 참과 거짓의 정보만 알 수 있을 때 사용합니다.로그인 폼에SQL Injection이 가능하다고 가정 했을 때,서버가 응답하는 로그인 성공과 로그인 실패 메시지를 이용하여, DB의 테이블 정보 등을 추출해 낼 수 있습니다.
Blind SQL Injection – Boolean based
위의 그림은Blind Injection을 이용하여 데이터베이스의 테이블 명을 알아내는 방법입니다. (MySQL)인젝션이 가능한 로그인 폼을 통하여 악의적인 사용자는 임의로 가입한abc123이라는 아이디와 함께abc123’ and ASCII(SUBSTR(SELECT name From information_schema.tables WHERE table_type=’base table’ limit 0,1)1,1)) > 100 --이라는 구문을 주입합니다.
해당구문은MySQL에서 테이블 명을 조회하는 구문으로limit키워드를 통해 하나의 테이블만 조회하고, SUBSTR함수로 첫 글자만,그리고 마지막으로ASCII를 통해서ascii값으로 변환해줍니다.만약에 조회되는 테이블 명이Users라면‘U’자가ascii값으로 조회가 될 것이고,뒤의100이라는 숫자 값과 비교를 하게 됩니다.거짓이면 로그인 실패가 될 것이고,참이 될 때까지 뒤의100이라는 숫자를 변경해 가면서 비교를 하면 됩니다.공격자는 이 프로세스를 자동화 스크립트를 통하여 단기간 내에 테이블 명을 알아 낼 수 있습니다.
Blind SQL Injection
Time based SQL
Time Based SQL Injection도 마찬가지로 서버로부터 특정한 응답 대신에 참 혹은 거짓의 응답을 통해서 데이터베이스의 정보를 유추하는 기법입니다.사용되는 함수는MySQL기준으로SLEEP과BENCHMARK입니다.
Blind SQL Injection - Time based
위의 그림은Time based SQL Injection을 사용하여 현재 사용하고 있는 데이터베이스의 길이를 알아내는 방법입니다.로그인 폼에 주입이 되었으며 임의로abc123이라는 계정을 생성해 두었습니다.악의적인 사용자가abc123’ OR (LENGTH(DATABASE())=1 AND SLEEP(2)) –이라는 구문을 주입하였습니다.여기서LENGTH함수는 문자열의 길이를 반환하고, DATABASE함수는 데이터베이스의 이름을 반환합니다.
주입된 구문에서, LENGTH(DATABASE()) = 1가 참이면SLEEP(2)가 동작하고,거짓이면 동작하지 않습니다.이를 통해서 숫자1부분을 조작하여 데이터베이스의 길이를 알아 낼 수 있습니다.만약에SLEEP이라는 단어가 치환처리 되어있다면,또 다른 방법으로BENCHMARK나WAIT함수를 사용 할 수 있습니다. BENCHMARK는BENCHMARK(1000000,AES_ENCRYPT('hello','goodbye'));이런 식으로 사용이 가능합니다.이 구문을 실행 하면 약4.74초가 걸립니다.
Stored Procedure SQL Injection
저장된 프로시저 에서의SQL Injection
저장 프로시저(Stored Procedure)은 일련의 쿼리들을 모아 하나의 함수처럼 사용하기 위한 것입니다.공격에 사용되는 대표적인 저장 프로시저는MS-SQL에 있는xp_cmdshell로 윈도우 명령어를 사용할 수 있게 됩니다.단,공격자가 시스템 권한을 획득 해야 하므로 공격난이도가 높으나 공격에 성공한다면,서버에 직접적인 피해를 입힐 수 있는 공격 입니다.
Mass SQL Injection
다량의SQL Injection공격
2008년에 처음 발견된 공격기법으로 기존 SQL Injection 과 달리 한번의 공격으로 다량의 데이터베이스가 조작되어 큰 피해를 입히는 것을 의미합니다. 보통 MS-SQL을 사용하는 ASP 기반 웹 애플리케이션에서 많이 사용되며, 쿼리문은 HEX 인코딩 방식으로 인코딩 하여 공격합니다. 보통 데이터베이스 값을 변조하여 데이터베이스에 악성스크립트를 삽입하고, 사용자들이 변조된 사이트에 접속 시 좀비PC로 감염되게 합니다. 이렇게 감염된 좀비 PC들은 DDoS 공격에 사용됩니다.
SQL Injection에서 사용되는 기법과 키워드는 엄청나게 많습니다.사용자의 입력 값에 대한 검증이 필요한데요.서버 단에서 화이트리스트 기반으로 검증해야 합니다.블랙리스트 기반으로 검증하게 되면 수많은 차단리스트를 등록해야 하고,하나라도 빠지면 공격에 성공하게 되기 때문입니다.공백으로 치환하는 방법도 많이 쓰이는데,이 방법도 취약한 방법입니다.예를 들어 공격자가SESELECTLECT라고 입력 시 중간의SELECT가 공백으로 치환이 되면SELECT라는 키워드가 완성되게 됩니다.공백 대신 공격 키워드와는 의미 없는 단어로 치환되어야 합니다.
Prepared Statement구문사용
Prepared Statement구문을 사용하게 되면,사용자의 입력 값이 데이터베이스의 파라미터로 들어가기 전에DBMS가 미리 컴파일 하여 실행하지 않고 대기합니다.그 후 사용자의 입력 값을 문자열로 인식하게 하여 공격쿼리가 들어간다고 하더라도,사용자의 입력은 이미 의미 없는 단순 문자열 이기 때문에 전체 쿼리문도 공격자의 의도대로 작동하지 않습니다.
Error Message노출 금지
공격자가SQL Injection을 수행하기 위해서는 데이터베이스의 정보(테이블명,컬럼명 등)가 필요합니다.데이터베이스 에러 발생 시 따로 처리를 해주지 않았다면,에러가 발생한 쿼리문과 함께 에러에 관한 내용을 반환헤 줍니다.여기서 테이블명 및 컬럼명 그리고 쿼리문이 노출이 될 수 있기 때문에,데이터 베이스에 대한 오류발생 시 사용자에게 보여줄 수 있는 페이지를 제작 혹은 메시지박스를 띄우도록 하여야 합니다.
웹 방화벽 사용
웹 공격 방어에 특화되어있는 웹 방화벽을 사용하는 것도 하나의 방법입니다.웹 방화벽은 소프트웨어 형,하드웨어 형,프록시 형 이렇게 세가지 종류로 나눌 수 있는데 소프트웨어 형은 서버 내에 직접 설치하는 방법이고,하드웨어 형은 네트워크 상에서 서버 앞 단에 직접 하드웨어 장비로 구성하는 것이며 마지막으로 프록시 형은DNS서버 주소를 웹 방화벽으로 바꾸고 서버로 가는 트래픽이 웹 방화벽을 먼저 거치도록 하는 방법입니다.
일반적으로 데이터베이스의 트리거(특정 상황이 발생하면 자동으로 실행되는 저장 프로시져)를 사용할 경우 제공되는 기능중에 inserted와 deleted라는 이름의 특별한 테이블들이 있습니다. 수정 작업시에 수정전의 데이터와 수정 후의 데이터를 갖고 있는 테이블을 지정해서 사용할 경우 접근할 수 있는 특별한 테이블입니다. 트리거를 사용하는 경우가 아니면 이러한 특별한 테이블에 접근할 수 있습니다. 그러나 SQL Server 2005부터는 OUTPUT문장을 지원함으로 일반 INSERT, UPDATE, DELETE문장에서도 이런 특별한 테이블에 접근할 수 있습니다. 테이블 변수를 선언한 후에 접근이 필요한 값을 OUTPUT문장을 사용해서 값을 담아서 사용할 수 있습니다. 다만 예외 상황도 있는데 아래와 같은 경우는 해당되지 않습니다. * 뷰를 대상으로 하는 INSERT구문인 경우 * 원격지의 테이블이나 뷰에 대한 DML문인 경우 * 로컬 또는 분산된 파티션 뷰에 대한 DML문인 경우
아래의 예제는 INSERT에서 OUTPUT절을 사용하는 경우입니다. 입력된 데이터를 테이블 변수에 담아서 그 값을 출력해 보았습니다. INSERT구문을 보면 VALUES앞쪽에 OUTPUT절을 사용해서 inserted.ProductModelID와 suser_name()함수를 지정했습니다. 지금 입력되는 레코드의 ProductModelID값과 접속한 유저이름을 @insert란 이름의 테이블 변수에 담도록 했습니다. 어떤 제품이 입력되고 누가 작업했는지를 확인할수 있습니다.
형식 INSERT INTO 데이터를 삽입할 테이블 (데이터를 삽입할 컬럼 명) OUTPUT INSERTED.삽입된 값을 조회할 컬럼 명 VALUES (삽입할 데이터)
--OUTPUT키워드사용
DECLARE @insert TABLE
(ProductModelID int, InsertedBy sysname)
INSERT INTO Production.ProductModel(Name, ModifiedDate)
OUTPUT inserted.ProductModelID, suser_name() INTO @insert
VALUES('DVD 2.0', getdate())
SELECT * FROM @insert
이번에는 UPDATE구문에서 사용하는 예제도 보도록 합니다. UPDATE에서는 inserted, deleted 라는 열 접두사를 사용해서 입력된 값과 삭제된 값의 각 컬럼에 접근할 수 있습니다. @NameChange라는 이름으로 테이블 변수를 선언합니다. 여기에 새로 입력된 이름과 기존 이름을 담도록 합니다. 아래쪽의 Update절을 보면 INSERTED.ProductModelID는 새로 입력된 제품의 ID를 선택하고 DELETED.Name은 삭제된 제품의 이름을 선택해서 앞에서 만든 테이블 변수에 저장합니다. 저장된 값을 출력하면 수정된 제품의 이름이 어떻게 업데이트 되었는지 알 수 있습니다. 그리고 UPDATE 구문에서 사용하는 OUTPUT 절은 데이터가 변경될 때 변경되는 데이터로 인식하지 않고 데이터를 삭제했다가 다시 삽입되는 형식으로 인식하기 때문에 변경되기 전 데이터는 삭제된 데이터로 변경 후의 데이터는 삽입된 데이터로 판단합니다.
기본 형식 UPDATE 데이터를 변경할 테이블 SET 데이터를 변경할 컬럼 명 = 변경할 값 또는 식 OUTPUT DELETED.변경 전 조회할 컬럼 명, INSERTED.변경 후 조회할 컬럼 명 WHERE 데이터를 변경할 행의 조건
--UPDATE구문에서사용되는예제
DECLARE @NameChange TABLE
(ProductModelID int,
OldName nvarchar(50),
NewName nvarchar(50),
UpdateBy sysname)
UPDATE Production.ProductModel
SET Name = 'DVD 3.0'
OUTPUT INSERTED.ProductModelID, DELETED.Name, INSERTED.Name,
suser_name() INTO @NameChange
WHERE ProductModelID=133
select * from @NameChange
DELETE절에서 사용하는 경우입니다. 앞에서 사용되었던 내용들과 비슷합니다. 삭제작업을 한 내용을 담아서 사용하기 때문에 DELETED.을 붙여서 삭제된 데이터의 컬럼 데이터를 선택해서 담은 결과를 출력합니다.
--DELETE구문에서사용된예제
DECLARE @Delete TABLE
(ProductModelID int,
DeletedBy sysname)
DELETE Production.ProductModel
OUTPUT DELETED.ProductModelID, suser_name() INTO @Delete
WHERE ProductModelID=132
SELECT * FROM @Delete
테이블에 자동증가 컬럼의 값이 추가되었고, 증가된 값을 반환하고 싶은 경우 SCOPE_IDENTITY(), IDENT_CURRENT(), @@IDENTITY 함수를 사용하여 원하는 값을 얻을 수 있다.
세 함수는 자동증가 컬럼에 삽입된 값을 반환하기 때문에 비슷한 함수이지만, 차이점이 있어 주의해서 사용해야 한다.
아래의 결과를 보면 같은 값을 반환한다.
CREATE TABLE dbo.TEST_TBL (
COL1 INT IDENTITY(1,1)
, COL2 VARCHAR(10)
)
GO
INSERT INTO dbo.TEST_TBL (COL2) VALUES ('ABC')
INSERT INTO dbo.TEST_TBL (COL2) VALUES ('DEF')
INSERT INTO dbo.TEST_TBL (COL2) VALUES ('GHI')
GO
SELECT @@IDENTITY AS '@@IDENTITY'
, SCOPE_IDENTITY() AS 'SCOPE_IDENTITY()'
, IDENT_CURRENT('TEST_TBL') AS 'IDENT_CURRENT()'
GO
그렇다면 세 함수의 차이점은 무엇일까?
IDENT_CURRENT() 는 범위와 세션으로 제한되는 것이 아니라 지정된 테이블로 제한된다.
SCOPE_IDENTITY() 와 @@IDENTITY 는 현재 세션의 테이블에서 생성된 마지막 자동증가 컬럼을 반환한다.
그러나 SCOPE_IDENTITY() 는 현재 범위 내에 삽입된 값을 반환하고, @@IDENTITY 는 특정 범위로 제한되지 않는 차이점이 있다.
@@IDENTITY 는 트랜잭션 내에 여러번의 자동증가 컬럼이 있는경우 @@IDENTITY 값이 변하기 때문에 사용하는 것을 자제해야하고, SCOPE_IDENTITY() 는 트랜잭션 내에서 일정한 값을 계속 유지하고 있으므로 이 값으로 사용하여야 한다.