구글 번역으로 인한 발번역이 있습니다. 한국어 설정은 제일 하단에 기입했습니다.
전체 텍스트 검색 정보
정의의 도움으로 전체 텍스트 검색을 이해합시다.
간단한 정의
전체 텍스트 검색은 빠른 답변을 위해 문자 기반 데이터를 최적으로 검색하는 데 사용됩니다.
Microsoft 정의
SQL Server 및 Azure SQL Database (클라우드 버전의 SQL 데이터베이스)에서 전체 텍스트 검색을 사용하면 사용자와 응용 프로그램이 SQL Server 테이블의 문자 기반 데이터에 대해 전체 텍스트 쿼리를 실행할 수 있습니다.
전체 텍스트 쿼리 란?
전체 텍스트 쿼리는 텍스트 데이터가있는 열에 대해 작성되고 실행되어 데이터 패턴을 찾는 특수한 종류의 쿼리입니다. 이 문제에 대해서는 해당 열에 대해 전체 텍스트 검색을 활성화해야합니다.

적합성
전체 텍스트 검색은 다음 SQL Server 버전과 호환됩니다.
- SQL Server 2005 이상
- Azure SQL 데이터베이스
전문 검색 현대 버전
SQL 2016과 같은 최신 SQL Server 버전에서는 전체 텍스트 검색을 의미 검색과 함께 설치할 수 있습니다.
전체 텍스트 검색 – SQL Server 옵션
SQL Server를 설치할 때는 기본적으로 전체 텍스트 검색이 설치되지 않습니다. 원래 SQL Server를 설치하는 데 사용한 설정을 사용하여 현재 SQL 인스턴스에 더 많은 기능을 추가하여 선택적으로 설치해야합니다.
전체 텍스트 검색 – 데이터베이스 기본값
모든 SQL 데이터베이스는 기본적으로 전체 텍스트 검색과 함께 사용할 수 있습니다. SQL 데이터베이스에서 전체 텍스트 검색을 사용하기 전에 요구 사항을 제외하고 추가 설치가 필요하지 않습니다.
대소 문자 구분
Microsoft 문서에 따르면 전체 텍스트 검색은 대소 문자를 구분하지 않으므로 "제어판", "제어판"및 "제어판"이라는 단어는 모두 동일하게 취급됩니다.
전체 텍스트 검색 설정
언급했듯이 SQL Server를 설치하는 데 사용한 것과 동일한 설치 파일을 사용하여 기존 SQL Server 설치의 기능으로 전체 텍스트 검색을 추가해야합니다.
SQL Installer 실행
SQL Server 설치 관리자를 실행하여 시작하십시오. 저장하지 않고 설치 프로그램에서 직접 실행하려는 경우 드라이브로 마운트 할 수있는 옵션을 제공합니다.
설치 파일 실행
Setup.exe 파일을 클릭하여 SQL Server 설치를 실행하십시오.

기능으로 추가
설정 파일을 실행하자마자 일부 초기 검사가 수행됩니다. 이러한 검사가 통과되면 설치 탐색 모음 (섹션)에서 “기존 설치 옵션에 기능 추가” 를 선택해야합니다 .

현재 서버를 선택하십시오
다음으로 전체 텍스트 검색을 설치할 현재 / 잠재 서버를 선택하십시오. 우리의 경우 SQL 2016입니다.

추가 할 인스턴스 기능을 선택하십시오.
다음으로, 검색 할 전체 텍스트 및 의미 추출 추출 기능을 선택하십시오 (이전 SQL 버전에이 기능을 추가하면 의미 추출이 표시되지 않을 수 있음).

연습 전에이 기능을 이미 추가 했으므로 스크린 샷에서 회색으로 표시됩니다. 그러나 처음으로 추가하는 사람에게는 활성화되어 있고 약간의 시간이 걸리는 설치가 가능합니다.
전체 텍스트 검색 설치 상태 확인
전체 텍스트 검색이 설치되면 마스터 데이터베이스에 대해 다음 T-SQL 스크립트를 실행하여 확인할 수 있습니다.
-- Is Full-Text Search installed then 1 or 0
SELECT fulltextserviceproperty('IsFulltextInstalled') as [Full-Text Search]
전체 텍스트 검색을 사용하여 단어 및 구문 검색
이제 전체 텍스트 검색을 사용하여 단어 및 구에 대한 몇 가지 기본 검색 작업을 수행합니다.
샘플 데이터베이스 설정
전체 텍스트 검색의 기본 사용법을 이해하려면 다음과 같이 SQLDevBlogV6 이라는 샘플 데이터베이스를 설정하십시오 .
-- Create sample database (SQLDevBlogV6)
CREATE DATABASE SQLDevBlogV6;
GO
USE SQLDevBlogV6;
-- (1) Create Article table in the sample database
CREATE TABLE [dbo].[Article] (
[ArticleId] INT IDENTITY (1, 1) NOT NULL,
[Category] VARCHAR (50) NULL,
[Author] VARCHAR (50) NULL,
[Title] VARCHAR (150) NULL,
[Published] DATETIME2 (7) NULL,
[Notes] VARCHAR (400) NULL,
CONSTRAINT [PK_Article] PRIMARY KEY (ArticleId)
);
GO
-- (2) Populate the table with data
SET IDENTITY_INSERT [dbo].[Article] ON
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (1, N'Development', N'Atif', N'Introduction to T-SQL Programming ', N'2017-01-01 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (2, N'Testing', N'Peter', N'Database Unit Testing Fundamentals', N'2017-01-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (3, N'DLM', N'Sadaf', N'Database Lifecycle Management for beginners', N'2017-01-20 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (4, N'Development', N'Peter', N'Common Table Expressions (CTE)', N'2017-02-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (5, N'Testing', N'Sadaf', N'Manual Testing vs. Automated Testing', N'2017-03-20 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (6, N'Testing', N'Atif', N'Beyond Database Unit Testing', N'2017-11-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (7, N'Testing', N'Sadaf', N'Cross Database Unit Testing', N'2017-12-20 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (8, N'Development', N'Peter', N'SQLCMD - A Handy Utility for Developers', N'2018-01-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (9, N'Testing', N'Sadaf', N'Scripting and Testing Database for beginners ', N'2018-02-15 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (10, N'Development', N'Atif', N'Advanced Database Development Methods', N'2018-07-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (11, N'Testing', N'Sadaf', N'How to Write Unit Tests for your Database', N'2018-11-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (12, N'Development', N'Peter', N'Database Development using Modern Tools', N'2018-12-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (13, N'DLM', N'Atif', N'Designing, Developing and Deploying Database', N'2019-01-01 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (14, N'DLM', N'Peter', N'How to Apply Database Lifecycle Management', N'2019-02-10 00:00:00', NULL)
INSERT INTO [dbo].[Article] ([ArticleId], [Category], [Author], [Title], [Published], [Notes]) VALUES (15, N'Testing', N'Saqib', N'SQL Unit Testing Stored Procedures', N'2019-03-10 00:00:00', NULL)
SET IDENTITY_INSERT [dbo].[Article] OFF문구와 단어
전체 텍스트 검색의 맥락에서 더 많은 문구와 단어를 봅시다. 이렇게하면 전체 텍스트 검색을 통해 원하는 것을 더 잘 알 수 있습니다.
“ T-SQL 소개 ” 라는 문구는 문구이며“ 소개 ”및“ T-SQL ”은 중요한 단어입니다.
SQL Server에서 전체 텍스트 검색을 구현하는 단계
전체 텍스트 검색은 다음과 같은 방식으로 구현됩니다.
- 전체 텍스트 인덱스를 저장하기 위해 전체 텍스트 카탈로그를 만듭니다.
- 테이블 또는 인덱싱 된 뷰에서 전체 텍스트 인덱스를 정의하십시오.
- CONTAINS 또는 FREETEXT를 사용하여 전체 텍스트 검색 쿼리를 실행하여 단어 와 구 를 찾습니다 .
전체 텍스트 카탈로그 작성
따라서 샘플 데이터베이스 (SQLDevBlogV6)가 작성되고 채워졌습니다. 전체 텍스트 카탈로그를 만드는 것이 전체 텍스트 검색을 구현하는 첫 번째 단계입니다.
SQL Server의 개체 탐색기 로 이동하여 데이터베이스 노드를 확장 한 다음 SQLDevBlogV6 을 클릭하십시오 .

클릭 저장을 한 후 클릭하여 전체 텍스트 카탈로그를, 다음을 클릭 새로운 전체 텍스트 카탈로그를 :

카탈로그 이름을 DevBlogCatalog 로 입력하고 확인을 클릭하십시오 .

새로 작성된 전체 텍스트 카탈로그는 다음과 같습니다.

테이블에 전체 텍스트 인덱스 정의
Articles 테이블을 마우스 오른쪽 단추로 클릭하고 전체 텍스트 인덱스 를 클릭 한 다음 아래와 같이 전체 텍스트 인덱스 정의 를 클릭 합니다.

전체 텍스트 인덱싱 마법사가 트리거됩니다. 클릭 다음 , 다음을 클릭합니다 다음을 다시 테이블에 기본 키가 마법사에 의해 미리 선택되어 있는지 확인한 뒤.

다음 단계에서 전체 텍스트 쿼리에 대한 제목 열을 선택하십시오 . 다음은 전체 텍스트 쿼리를 실행할 열입니다.

그런 다음 아래와 같이 자동 옵션 (다른 옵션을 선택하지 않는 경우)을 선택하여 변경 내용 추적을 자동화하는 기본 옵션을 선택하십시오 .
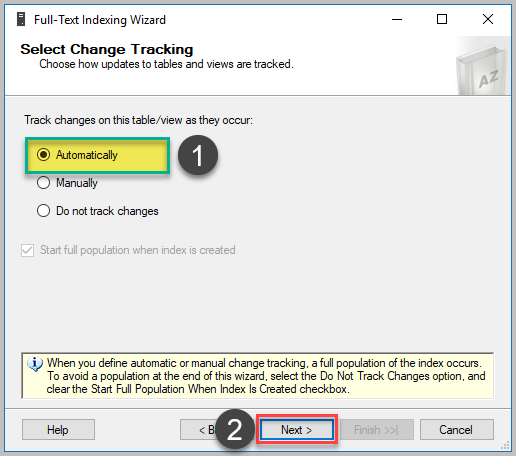
다음 단계에서는이 연습에서 앞에서 정의한 전체 텍스트 색인과 연결할 전체 텍스트 카탈로그 (DevBlogCatalog)를 선택하십시오. 그런 다음 아래와 같이 기본 옵션을 선택한 후 다음을 클릭하십시오.

클릭 다음을 하고 선택적인 단계를 건너 뛰고, 다음을 클릭합니다 마침을 전체 텍스트 색인이 성공적으로 생성 된 것을 볼 수 있습니다.

이제 전체 텍스트 검색을 활성화하여 기사 테이블 의 제목 열에 대해 전체 텍스트 쿼리를 실행할 수 있습니다 .
전체 텍스트 쿼리를 사용하여 단어 테스트 검색
다음 T-SQL 스크립트를 작성하여 CONTAINS 키워드 (조건 자)를 사용하여 단어를 빠르게 검색 할 수 있습니다 .
-- Search for the Word Testing using Full-Text Query
SELECT * FROM dbo.Article
WHERE CONTAINS(Title,'Testing')제목 열 에서 테스트 단어 를 검색 한 결과 는 다음과 같습니다.

전체 텍스트 검색없이 Like 연산자를 사용하여 동일한 결과를 얻을 수 있습니다. 차이점은 수백만 행과 수백만 행에 대해이 쿼리를 실행할 때와 LIKE 연산자가 어려움을 겪을 때입니다. 한편 전문가에 따르면 CONTAINS는 훨씬 빠릅니다.
전체 텍스트 쿼리를 사용하여 초보자를위한 구문 검색
제목에 "초보자를위한" 이라는 문구 가 사용 된 모든 기사를 찾아 보겠습니다 . 이것은 초보자가 빨리 시작할 수 있도록 도와줍니다.
이번에는 FREETEXT 키워드 (Predicate)를 사용하고 있습니다. 다음 T-SQL 스크립트를 사용하여 초보자를위한 모든 기사를 얻을 수 있습니다.
-- Search for Phrase: for beginners using Full-Text Query
SELECT * FROM dbo.Article
WHERE FREETEXT(Title,'for beginners')
축하합니다. 전체 텍스트 검색의 기본 사항을 성공적으로 익혔습니다. 단어와 구에 대한 전체 텍스트 검색 쿼리를 설정하고 실행하는 실습 경험도 있습니다.
다음 기사에서 고급 전체 텍스트 검색 사용법을 설명하므로 계속 연락하십시오. 데이터베이스 분석 시나리오에서 종종 유용합니다.
해야 할 일
전체 텍스트 검색을 설정하고 전체 텍스트 쿼리를 실행할 수 있으므로 다음을 시도하여 기술을 향상 시키십시오.
- 기사에 대한 자세한 정보를 제공 하여 데이터베이스 Notes 열을 채우십시오. CONTAINS 및 FREETEXT 키워드를 사용하여 단어와 구를 검색하려면 전체 텍스트 카탈로그를 정의하고 전체 텍스트 쿼리를 실행해야합니다.
- 또한 단어 단위 를 검색 하여이 단어가 언급 된 모든 기사를 찾으십시오. 열에 단위 테스트, 단위 테스트 또는 단위 테스트로 저장 될 수 있습니다.
- 이 기사 의 샘플 데이터베이스를 참조하십시오 . 전체 텍스트 설정 Product 테이블을 검색 하고 열 이름 에 전체 텍스트 인덱스를 정의하고 가능한 한 많은 레코드를 추가하십시오. 원하는 단어와 구를 검색하여 원하는 제품 (이름)을 찾으십시오.
원본 : https://codingsight.com/implementing-full-text-search-in-sql-server-2016-for-beginners/
++ 한국어 설정
위의 설정대로 따라하면 한국어가 설정이 되지않아 FREETEXT가 제대로 작동하지 않는것을 확인할 수 있다.
1. 사용하는 데이터 베이스 - Storage - Full Text Catalogs - 상단에서만든카타로그 오른쪽클릭
2. Properties 클릭 (sql server manager를 한국어로 설정했다면 속성)
3. Tables/Views 탭 클릭
4. 해당 탭에서 하단의 Eligible columns 를 보면 이 글의 상단에서 Full-Text query를 사용할 column들이 보인다.
5. 체크한 column들의 Language for Word Breaker 가 영어로 설정되어 있을것인데 모두 Korean으로 바꿔준다.
6. ok로 설정 완료
'DB > MSSQL' 카테고리의 다른 글
| MSSQL) Full Text Searching - 전체 텍스트 인덱스 관리 (0) | 2020.06.12 |
|---|---|
| MSSQL) Full Text Search(FREETEXTABLE) 관리 및 데이터 쿼리 모음 (0) | 2020.06.12 |
| MS-SQL with (nolock) 란? (0) | 2020.06.03 |
| [MSSQL] 조건문 (CASE WHEN, IF) 함수 사용법 & 예제 (0) | 2020.05.12 |
| [MSSQL] DATEADD 사용법 / 날짜 및 시간 더하기 / 날짜 및 시간 빼기 (0) | 2020.04.29 |




