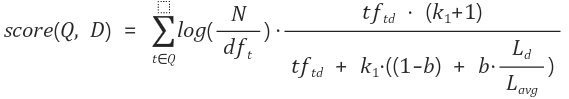반응형
-- Compute fragmentation information for all full-text indexes on the database
SELECT c.fulltext_catalog_id, c.name AS fulltext_catalog_name, i.change_tracking_state,
i.object_id, OBJECT_SCHEMA_NAME(i.object_id) + '.' + OBJECT_NAME(i.object_id) AS object_name,
f.num_fragments, f.fulltext_mb, f.largest_fragment_mb,
100.0 * (f.fulltext_mb - f.largest_fragment_mb) / NULLIF(f.fulltext_mb, 0) AS fulltext_fragmentation_in_percent
FROM sys.fulltext_catalogs c
JOIN sys.fulltext_indexes i
ON i.fulltext_catalog_id = c.fulltext_catalog_id
JOIN (
-- Compute fragment data for each table with a full-text index
SELECT table_id,
COUNT(*) AS num_fragments,
CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS fulltext_mb,
CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mb
FROM sys.fulltext_index_fragments
GROUP BY table_id
) f
ON f.table_id = i.object_id출처: https://stackoverflow.com/questions/16061248/how-to-optimize-a-sql-server-full-text-search
반응형
'DB > MSSQL' 카테고리의 다른 글
| MsSQL) Non Clustured index 를 Clustured index로 바꾸기 (0) | 2020.06.18 |
|---|---|
| [MSSQL] WHERE CASE WHEN 조건절에 조건문 (0) | 2020.06.17 |
| MSSQL) Full Text Searching - 전체 텍스트 인덱스 관리 (0) | 2020.06.12 |
| MSSQL) Full Text Search(FREETEXTABLE) 관리 및 데이터 쿼리 모음 (0) | 2020.06.12 |
| SQL SERVER 2016 Full-Text Search 세팅하기 (+ 한국어 설정까지) (0) | 2020.06.11 |