Okapi BM25는 검색엔진, 추천 시스템 등에서 사용되는 스코어링 알고리즘이다.
tf(term frequency) 와 idf(inversed document frequency) 의 개념을 바탕으로,
문서의 길이까지 고려를 하여 스코어링을 한다.
Okapi BM25의 기본적인 식은 다음과 같다.
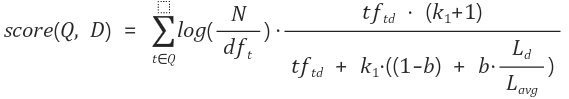
식이 꽤 복잡해 보이지만 알고 보면 tf, idf, 문서 길이만 factor로 사용하며
나머지는 이 세 가지 요소들을 어떻게 weight를 주어 스코어링을 할 것인지를 결정하는 부분이다.
식을 처음부터 살펴보자.
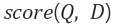
Document (D) 에 Query (Q) 를 날려 얼마나 일치하는지 score를 얻는 것이 목적이다.
만약 검색에서 이 알고리즘을 사용한다면, score가 높은 순서대로 Document가 정렬되어 검색 결과로 나타날 것이다.

Query를 쪼개면 여러 개의 term이 생길 것이다.
제일 쉽게는 띄어쓰기를 기준으로 쪼갤 수 있을 것이다.
각 term을 Document에 적용한 결과를 모두 더하여 score가 결정된다.
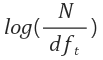
idf의 식이다.
해당 term을 가지고 있는 문서의 갯수 / 전체 문서의 갯수 (=df) 를 역수 취하고 로그를 씌운 값이다.
보통 N이 매우 크기 때문에 로그를 씌워 값의 range를 좁혀준다.
(Document set이 1000000개의 Document들로 이루어져 있고, 그 중 검색하는 term이 나온 문서가 10개라면
로그를 씌우지 않았을 때는 값이 100000 이지만, 로그를 씌우면 5가 된다.)

제일 복잡해 보이는 식이다.
일단 tf(td) 는 말 그대로 Document d에서 t라는 term이 얼마나 나타났는지 그 count를 나타내는 것이고,
L(d) 는 현재 Target Document d의 길이,
L(avg) 는 전체 Document set에 있는 모든 Document 길이의 평균을 나타낸다.
(여기서 Document의 길이라 함은 term이 몇개인가? 라고 이해하면 되겠다.)
나머지 k1과 b는, tf와 L값을 어떻게 weight를 주어 계산을 해 줄건지 결정하는 parameter라고 보면 된다.
k1이 0이라면? 모든 텀은 다 지워지고 저 식이 통째로 1이 되겠다.
결국 tf고 L이고 뭐고 아무것도 고려를 안 하겠다는 말이 된다.
k1이 높아지면 높아질수록 tf에 많은 가중치를 두어 계산한다는 뜻이 된다.
그럼 b가 0이라면? 문서의 길이를 고려하지 않겠다는 말이 되고
b가 1에 가까워질수록 문서의 길이에 많은 가중치를 두어 계산한다는 뜻이 되겠다.
(k1과는 달리 b는 1을 넘을 수 없다.)
실험적으로, k1은 1.2와 2.0 사이, b는 0.75로 설정하는 것이 제일 올바른 스코어링을 하게 한다고 하지만
어떤 도메인에서 어떤 검색을 실행할 것인가에 따라 두 값을 조정하여 알고리즘을 튜닝할 수 있겠다.
어쨌든 보자면, score가 높아지려면 tf(td) 의 값은 높아져야 하고,
L(d) / L(avg) 의 값은 낮아져야 한다는 것을 알 수 있다.
여기서 tf는 그렇다 쳐도 문서의 길이는 왜 따지냐고 할 수 있는데, 이것도 간단하다.
100단어로 이루어진 문서 중 내가 날린 term이 한번 나오는 것과,
1000단어로 이루어진 문서 중 내가 날린 term이 한번 나오는 것은 매우 다르기 때문이다.
짧은 문서에서 내가 찾는 핵심 term만 딱! 나오는 게,
긴 문서에서 주저리주저리 하다가 어쩌다 내가 찾는 term이 한번 나오는 것보다는 훨씬 매칭이 잘 되는 문서일 것이다.
이제 총정리를 하면, 어떤 문서와 쿼리가 매칭이 잘 되어 높은 score를 얻기 위해서는 :
1. 내가 날린 query 안의 term이 적은 문서에만 있는, 즉 매우 희소하고 자주 쓰이지 않는 단어여야 하며,
2. 문서에서 해당 term이 많이 나와야 하며,
3. 해당 문서의 길이는 짧아야 한다.
로 요약할 수 있겠다!
근데 저 공식은 매우 기본적인 형태이고, 실질적으로 검색 서비스에 사용되는 랭킹 알고리즘은 훠어어어어어얼씬 더 많은 피쳐들을 알고리즘에 적용한다.
출처: https://jitwo.tistory.com/8 [jitwo]
'DB > .etc' 카테고리의 다른 글
| SQL Injection 이란? (SQL 삽입 공격) (0) | 2020.04.27 |
|---|---|
| [Postman] Mock Server / API Documentation 만들기 (0) | 2020.04.17 |