IMO: Converting video to gif is a terrible hack of convenience
요즘에는 통신망의 발달과 디바이스 성능의 개선으로 인해 어딜 가나 다양한 형식의 미디어를 즐길 수 있게 되었습니다.
GIF is everywhere (Image Source)
그 중 GIF는 우리가 흔히 볼 수 있는 이미지 포맷 중 하나인데, 보통 “움직이는 짤방" 혹은 줄여서 “짤방" 으로 표현하기도 합니다. 요즘에는 어딜 가나 GIF를 볼 수 있고, 아예 모바일 디바이스의 키보드에서 GIF를 바로 첨부할 수 있도록 그 인기는 날이 갈수록 치솟아가고 있죠.
하지만, 우리는 이제 움직이는 GIF (Animated GIF)를 쓰지 말아야 합니다. 움직이는 GIF는 올해로 30살이 된 오래된 규격이며, 비효율적입니다.
도대체 얼마나 비효율적이냐구요? 한번 알아봅시다.
Compression Efficiency
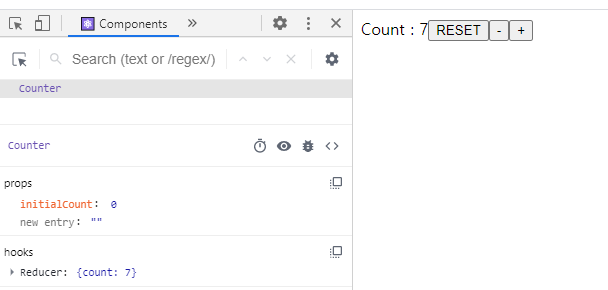
First frame comparison between two file formats.
여기 각각 다른 포맷에서 동일한 프레임을 캡쳐한 두 이미지가 있습니다. 여러분들은 시각적으로 “두 포맷간 품질의 차이"를 느끼실 수 있으신가요?
글쎄요, 저는 잘 모르겠네요.
놀랍게도 두 포맷의 품질 차이는 거의 느낄 수 없지만, 파일 크기는 무려 10배 이상 차이가 납니다.
File size comparison between two animated image files
이렇게 큰 파일 크기 차이가 발생하는걸 보면, GIF는 정말 “거품” 입니다. 서비스를 운영하는 쪽 뿐만 아니라, 서비스를 사용하는 유저에게도 손해입니다.
GIF는 불필요하게 대역폭을 낭비해 엄청나게 많은 전송량을 발생시킵니다.
특히 대역폭이나 사용량이 제한되어 있는 모바일 네트워크에서는 그 손해가 더 크게 느껴질 수 밖에 없습니다.
자, 아래 동영상은 대역폭을 제한한 상태에서 각 두 포맷을 재생한 것입니다. 한번 보시죠. (두 비디오 모두 MP4 Video -> GIF 순입니다)
Single Animated Image on 3Mbps Mobile Network
Multiple Animated Image on 10Mbps Wi-Fi Network
H.264 MP4의 경우 대부분 재생이 원활하고 데이터를 적게 소모한 반면, GIF는 재생이 원할하지도 않고 데이터 소모도 엄청납니다! 특히 4개의 Animated Image를 보여주는 페이지에서는 총 GIF 파일의 크기가 100MByte를 넘어서는것을 확인할 수 있습니다. 엄청 크죠?
그 이유는, 각 포맷의 특성에 있습니다.
GIF의 경우 256색을 표현할 수 있는 컬러 팔레트와, 각 프레임의 모든 픽셀에 대한 정보를 무손실 압축 데이터로 담고 있으며 , H.264를 포함한 비디오 포맷들은 기본적으로 손실 압축이고, GIF와는 비교가 안될 정도로 다양한 최적화 기술들이 들어가있습니다.
예를 들면 아래와 같은 기술들이 있습니다:
- 프레임간 달라지는 픽셀에 대한 정보만 담고, 다양한 예측 모델을 사용한다
(I/B/P Frame, Inter/Intra prediction, transform, quantization, entropy encoding…)
- 사람의 시각이 색보다 빛을 더 민감하게 받아들인다는 점을 이용해, 색상 정보를 줄이려고 시도한다 (YCbCr Color Model, Chroma Subsampling)
그래서 발전된 기술들이 많이 쌓인 비디오 포맷들이 GIF보다 더 나은 압축 효율을 보여줄 수 있는 것입니다.
자, 우리는 이제 GIF가 효율이 정말 좋지 않다는걸 직접 확인했습니다. 근데 그것말고도 GIF를 쓰지 말아야 할 이유가 아직 더 남아있습니다.
Decoding Performance
이번에 이야기 할 주제는, 디코딩 성능입니다.
2000년 초까지만 해도 압축된 비디오 데이터를 해석하는 것 (디코딩)은 온전히 CPU의 몫이었습니다. 2005년 즈음부터 MPEG-TS를 시작으로 GPU를 통해 하드웨어 디코딩이 가능하기 시작했죠. 물론 요즘 우리가 쓰는 스마트폰에 탑재된 프로세서도 하드웨어 디코딩을 지원합니다.
하드웨어 디코딩이 중요한 이유는, GPU를 통해 디코딩을 처리하는게 훨씬 전력 효율이 좋기 때문입니다. 아무리 CPU의 연산 성능이 좋아졌다곤 하지만, GPU는 아예 디코딩을 위한 블럭들이 칩에 박혀있기 때문에 그 효율을 따라갈 수 없습니다. 만약 GPU를 통한 하드웨어 디코딩이 가능하지 않았더라면, 스마트폰에서 Youtube 비디오를 2시간 넘게 즐기는건 불가능했었을겁니다.
제가 여기서 “하드웨어 디코딩" 을 이야기 하는 이유는, 바로 GIF 이미지를 디코딩하는것은 GPU에서 처리하지 못하기 때문입니다. H.264/AVC 비디오의 경우 대부분의 디바이스에서 하드웨어 디코딩이 가능합니다. 라즈베리파이에서도 되거든요.
이번에도 비디오를 가져왔습니다. 먼저, 데스크탑 브라우저에서의 디코딩 성능 차이를 보시죠: (MP4 Video -> GIF 순입니다)
Instrumented macOS WebKit Processes
처음이 H.264 MP4 비디오 재생, 두번째가 GIF 이미지 재생입니다. Instrument App의 CPU Activity Graph와 Live Processes Table를 보시면 확실히 GIF 이미지를 재생할 때 더 많은 CPU 자원을 소모하는 것을 확인할 수 있습니다.
여기서 흥미로운 점이 있다면, GIF 이미지의 경우 Paint가 계속 일어나는것으로 찍히는 반면, H.264 MP4 Video의 경우 Paint가 찍히지 않습니다.
Chrome에서도 비슷하게 나타납니다. 아마도 GIF의 경우 이미지 디코딩을 CPU에서 직접 처리하고, Video의 경우 GPU에서 직접 처리되어서 이에 따른 차이가 발생하는 것으로 추측됩니다.
(혹시라도 이 부분에 대해 자세히 알고 계신 분이 계시다면 댓글 남겨주시면 감사하겠습니다 :))
(MP4 Video -> GIF 순입니다)
Chrome Raster Thread metrics
각 포맷을 로드할때의 CPU Usage 차이가 보이시나요? 게다가 비디오가 훨씬 더 균일한 FPS를 보여줍니다.
이번에는 iPhone X의 iOS Safari에서 테스트 한 영상입니다. (MP4 Video -> GIF 순입니다)
Instrumented macOS WebKit Processes
여기서는 몇가지 지표를 더 확인할 수 있는데, H.264 MP4 비디오를 재생할 때 Graphics Activity가 더 높은걸 확인할 수 있습니다. 그리고 역시 GIF 이미지를 재생할때 더 높은 CPU 사용량을 보입니다.
더 높은 CPU 사용량을 보인다는 것은, 더 많은 배터리를 소모한다는 이야기이기도 합니다. 또한, 저사양 디바이스에서 원할한 재생이 어려울 수도 있겠죠.
그 이외에도 GIF를 피해야 하는 이유는 많습니다.
컬러 팔레트에서 최대 사용가능한 색상의 수가 256색으로 제한되어 있어 색 표현에 제약이 있으며,
일부 브라우저에서 재생 가능한 FPS (Frame rate speed)가 제한 되어 있기도 합니다.
GIF is not designed for Animation
The Graphics Interchange Format is not intended as a platform for animation, even though it can be done in a limited way. — GIF89a Specification
마지막으로, GIF89a 규격을 보면 “GIF는 애니메이션을 위해 디자인 되지 않음”이 명시되어 있습니다.
Platform Compatibility
이정도면 이제 GIF보다 비디오를 쓰는게 더 낫다는건 충분히 이해하실겁니다. 그런데 “호환성"이 걱정되신다고요? 그러실 줄 알고 미리 준비했습니다.
H.264 비디오는 대부분의 플랫폼에서 호환이 되므로, 걱정할 필요가 없습니다. 그냥 쓰세요!
제가 개인적으로 권장하고, Vingle에서 사용하고 있는 Animated Image (GIF)용 비디오 규격은 다음과 같습니다:
- MP4 Container
- H.264/AVC, Baseline Profile, Level 3.1
Recommended encoder: x264
- Maximum resolution: 540p (960 * 540)
- CRF rate control mode
Target CRF: 22 ~ 24 / Maximum Bitrate: 1600K / Buffer size: 2400K)
- YUV420 Color space/Chroma Subsampling
- No Audio
위 규격은 Vingle이 지원하는 모든플랫폼 (IE 10+, Android 4.1.4+, iOS 9+) 에서 재생이 가능합니다.
How to play video?
비디오를 클라이언트에서 재생하기 위해서는, 몇가지 변경사항이 필요합니다. 플랫폼별로 필요한 변경사항들을 나열해보면 다음과 같습니다:
Web
저게 전부입니다! 웹은 정말 간단하죠?
참고로 iOS Safari의 경우, iOS 10 부터 새로운 비디오 정책이 적용되어 autoplay에 제약이 생겼습니다만, 예외적으로 muted attribute를 준 경우 autoplay가 허용됩니다.
Source: https://webkit.org/blog/6784/new-video-policies-for-ios/
또한, playsinline attribute를 주지 않으면 비디오가 “전체 화면" 으로 재생되니 주의하세요!
Android
Android의 경우 보통 이미지 뷰어로 Facebook에서 만든 Presco를 사용하는데, 비디오를 재생하려면 Presco 대신 별도의 비디오 플레이어 라이브러리를 사용해야 합니다. 저는 Vingle Android App에서 사용중인 ExoPlayer를 추천합니다.
iOS
iOS의 경우 iOS팀의 현수님이 쓰신 글로 대신합니다 :)
How to convert GIF to Video?
비디오를 재생하려면 GIF로 비디오로 변환하는 작업 또한 필요합니다.
여기서는, 크게 두가지 경우로 나누어 설명하겠습니다.
일반 사용자 혹은 플랫폼 내에서 비디오 변환이 꼭 필요하지 않은 경우
더이상은 naver…
위와 같이 클리앙과 같은 온라인 커뮤니티에 업로드 할 목적이거나, 일부 컨텐츠에 대해서만 GIF 대신 비디오로 보여줄 목적이라면, 별도 프로그램 없이도 변환할 방법이 있습니다. Giphy 같은 GIF 호스팅 서비스를 사용하는 방법입니다.
Giphy
Giphy에 변환하고자 하는 GIF를 업로드하면, Giphy가 GIF를 알아서 비디오로 변환해줍니다! 우리는 그 비디오를 그냥 다시 다운받기만 하면 되는거죠.
플랫폼 내에서 비디오 변환이 필요한 경우
플랫폼 내에 GIF 업로드 기능이 이미 있는 상태에서 비디오 변환을 추가하려면, 별도로 서버에서 비디오 변환을 처리해야합니다.
비디오 변환을 서버에서 직접 처리하는 경우, 저는 개인적으로 FFmpeg를 추천합니다. 위에서 언급한 권장 규격으로 출력하는 경우 ffmpeg 명령은 다음과 같습니다:
$ ffmpeg -i GIF_IMAGE_INPUT.gif -c:v libx264 -profile:v baseline -level 3.1 -crf 24 -maxrate 1600K -bufsize 2400K -pix_fmt yuv420p -an -movflags +faststart EFFICIENT_VIDEO_OUTPUT.mp4
GIF를 직접 비디오로 변환하는 경우, 주의해야 할 점이 몇가지 있습니다:
출력 비디오의 해상도가 반드시 2의 배수여야 합니다.
4:2:0 Chroma subsampling의 경우 해상도가 2의 배수여야 합니다.
만약 GIF 이미지의 가로 또는 세로 크기가 홀수면, 아래와 같은 에러를 출력하고 비디오 변환에 실패합니다.
[libx264 @ 0xa3b85a0] height not divisible by 2 (520x369)
이 경우, scale이나 crop 같은 video filter를 사용해 출력 해상도를 제어하시면 됩니다.
아래는 scale filter를 사용하는 예 입니다:
-vf "scale=trunc(iw/2)*2:trunc(ih/2)*2"
MP4 container의 moov atom을 앞쪽으로 옮겨야 합니다
(다소 주제가 어려울 수 있겠지만, 이 내용을 최대한 쉽게 설명드리겠습니다.)
MP4 컨테이너의 경우 여러개의 청크로 구성되어 있습니다. 그리고 청크를 atom 이라고 부릅니다.
atom 은 비디오 데이터, 오디오 데이터, 챕터 정보와 같은 메타데이터 등 여러 타입이 있는데, 그 중 moov atom이 있습니다. moov atom은 일종의 목차 같은 역할을 합니다. “재생을 시작할 비디오/오디오 데이터의 위치" 를 담고있는거죠.
Example atom tree
여러분들이 MP4 비디오를 재생하면, 플레이어들은 비디오를 재생하기 위해 내부적으로 이 moov atom을 찾게됩니다. 하지만 정말 불행하게도, atom들의 순서는 정해져있지 않습니다. 즉, 만약 moov atom이 맨 끝의 atom 이라면, 파일을 다 읽어들이기 전까지는 재생을 시작하지 못합니다. 비디오 데이터가 파일의 어디에 있는지 moovatom을 읽기 전까지는 특정할 수 없으니까요.
MP4 비디오가 로컬에 있는 경우에는 디스크에서 탐색을 수행하기 때문에 그래도 괜찮지만, 문제는 네트워크를 통해 MP4 비디오를 스트리밍 하는 경우입니다. moov atom을 찾기 전까지는 비디오 재생이 아예 불가능하기 때문입니다.
요즘 대부분의 모던 브라우저들은 Range Request Header를 사용해 MP4 파일을 탐색 (seek) 하도록 구현이 되어 있지만, 여러 요청을 주고 받기 때문에 네트워크 지연으로 인해 재생을 시작하기까지 시간이 다소 소요될 수 있습니다.
Multiple MP4 Requests explaination
최악의 상황은, 만약 웹서버가 Range 헤더를 읽어 Partial Content Response를 지원하지 않는 경우입니다. 이 경우 비디오 파일을 모두 다운로드 받기 전까지는 재생을 시작할 수 없습니다.
아래 비디오를 통해 Partial Content Response 지원 유무에 따른 그 차이를 확인해보세요:
Comparison of Partial Content Response support
moov atom을 맨 앞으로 옮긴 경우, 이러한 seeking이 필요가 없기 때문에 단일 요청을 보내고 응답을 받자마자 즉시 재생을 시작할 수 있습니다. 또한, moov atom을 맨 앞으로 옮겨주었기 때문에 웹서버가 Partial Content response를 지원하지 않아도 걱정할 필요가 없습니다.
위에서 소개한 ffmpeg 명령에서도 moov atom을 맨 앞으로 옮기기 위해 -movflags +faststart 옵션을 사용합니다.
다음 이미지는 moov atom을 맨 앞으로 옮김으로서 단일 요청만으로 재생을 시작하는 것을 보여줍니다:
moov optimization can skip additional seeking steps
그 이외에도, 다양한 오픈소스 프로젝트들이 있으니 참고해보세요:
Vingle 에서 Video Pipeline을 구축한 관련 경험에 대해 궁금하시다면, 아래 슬라이드를 참고해주세요:
AWSKRUG Architecture Meetup — Serverless Media Workflow
또한, Google의 Addy Osmani가 작성한 Image Optimization Guide도 한번 읽어보시는걸 강력하게 추천합니다:
만약 컨버팅 프로세스를 직접 만들고 싶지 않다면, SaaS 제품을 사용하시는것도 괜찮은 방법입니다. 개인적으로 추천하는 플랫폼은 다음과 같습니다:
Why we don’t use WebP/WebM
아마 이런 생각을 하시는 분도 계실겁니다.
WebP/WebM을 대안으로 사용할 수 있지 않나요?
네. WebP나 WebM을 사용할 수도 있습니다. 하지만 저희는 다음과 같은 이유로 WebP와 WebM을 선택하지 않았습니다:
- WebP/WebM에 대한 플랫폼 지원이 아직까지는 많이 모자랍니다.
비 구글 제품에 대해 지원이 아직까지는 너무나도 빈약합니다. Web, Android, iOS에서 모두 사용할 수 있는 범용성이 필요했습니다.
- Adoption Rate이 아직 낮다고 판단했습니다.
H.264/AVC는 사실상의 산업 표준 (industry standard) 인 반면에, WebP/WebM은 사용하기에 적절할 정도로 널리 보급되지 않았습니다.
- 하드웨어 가속 디코딩에 대한 지원이 부족합니다.
- 낮은 Bitrate에서는 꽤 괜찮은 결과를 보여주지만, H.264/AVC 만큼 좋지는 않습니다.
또한, HEIC/HEIF나 HEVC와 같은 차세대 포맷을 생각한다면, 더욱 WebP나 WebM을 선택할 이유가 없었습니다. 그 이유는 다음과 같습니다:
HEIC/HEIF는 이미지를 위한 새로운 규격으로, MP4와 비슷한 일종의 컨테이너입니다. 내부적으로는 HEIC나 AVC로 이미지를 인코딩해서 쓸 수 있으며, 다양한 사용 사례들 (e.g. 스틸 이미지, 이미지 컬렉션, 이미지 시퀀스 — iOS의 Live Photo- 등)을 염두하고 디자인 된 규격이기 때문에 상당이 유연하고,
HEVC는 H.264/AVC 를 이어갈 코덱 (그래서 H.265/HEVC 라고 부르기도 합니다) 으로 H.264/AVC를 ‘뛰어넘는' 압축 효율을 가지고 있습니다.
게다가 두 포맷 모두 메이저 플랫폼 뿐만 아니라(iOS 11 / macOS High Sierra / Windows 10), GPU Vendor들(Intel, NVIDIA, AMD, Qualcomm) 이 지원을 시작했습니다.
HEIC/HEIF의 경우 아래 링크를 통해 다양한 사용 사례들을 확인하실 수 있으니 한번 참고해보세요!
Wrapping up
이야기 했던 내용들을 간단히 요약하면 다음과 같습니다.
- GIF는 거품 덩어리이며, 모두에게 손해다
H.264 Video로 변환하는 경우 10배 이상 크기를 줄일 수 있으며, 기기의 배터리에도 도움이 된다.
- GIF를 Video로 변환해서 제공하자
giphy, ffmpeg, cloudinary, imgix등 다양한 선택지가 존재하니 상황에 맞게 선택해라
GIF 대신 Video를 쓰기로 결정하셨다면 축하의 박수를! :)
빙글에서도 유저들이 올리는 말도안되는 사이즈의 GIF 때문에 아주 오랫동안고통을 받았는데요. (100MByte를 넘어가는 GIF 이미지들, 눈물 없이는 볼 수 없는 CDN 요금, 빙글 앱만 켜면 휴대폰이 손난로가 된다는 피드백… 😭)
다음 글에서는 저희가 어떻게 GIF -> Video Conversion process를 완벽히 serverless 구조로 만들었는지 이야기하고, Lambda와 S3를 사용해 직접 변환 프로세스를 구현하는 방법을 다루어보겠습니다.
다음에 또 만나요!
출처 : https://medium.com/vingle-tech-blog/stop-using-gif-as-animation-3c6d223fd35a