저의 경우 서버로 부터 값을 가져오거나 업데이트 하는 로직을 store 내부에 개발하는 경우가 많습니다. 그렇다보니 store는 클라이언트 state를 유지해야하는데 어느 순간부터 store에 클라이언트 데이터와 서버 데이터가 공존 하게 됩니다. 그리고 그 데이터가 서로 상호작용하면서 서버 데이터도 클라이언트 데이터도 아닌 끔찍한 혼종(?)이 탄생하게 됩니다. (예를 들면 서버에는 이미 패치된 데이터가 클라이언트에서는 패치되기 전 데이터가 유저에게 사용되고 있는 것이라고 볼 수 있습니다.)
그래서 react-query를 사용함으로 서버, 클라이언트 데이터를 분리합니다. 이 개념에 대해 동의 하지 않아도 아래의 장점을 보신다면 사용하고 싶은 생각이 드실 것입니다.
데이터를 get 하기 위한 api입니다. post, update는useMutation을 사용합니다.
첫번째 파라미터로 unique Key가 들어가고, 두번째 파라미터로 비동기 함수(api호출 함수)가 들어갑니다. (당연한 말이지만 두번째 파라미터는 promise가 들어가야합니다.)
첫번째 파라미터로 설정한 unique Key는 다른 컴포넌트에서도 해당 키를 사용하면 호출 가능합니다. unique Key는 string과 배열을 받습니다. 배열로 넘기면 0번 값은 string값으로 다른 컴포넌트에서 부를 값이 들어가고 두번째 값을 넣으면 query 함수 내부에 파라미터로 해당 값이 전달됩니다.
return 값은 api의 성공, 실패여부, api return 값을 포함한 객체입니다.
useQuery는비동기로 작동합니다.즉, 한 컴포넌트에 여러개의 useQuery가 있다면 하나가 끝나고 다음 useQuery가 실행되는 것이 아닌 두개의 useQuery가 동시에 실행됩니다.여러개의 비동기 query가 있다면 useQuery보다는 밑에 설명해 드릴useQueries를 권유드립니다.
enabled를 사용하면 useQuery를 동기적으로 사용 가능합니다. 아래 예시로 추가 설명하겠습니다.
const usersQuery = useQuery("users", fetchUsers);
const teamsQuery = useQuery("teams", fetchTeams);
const projectsQuery = useQuery("projects", fetchProjects);
// 어짜피 세 함수 모두 비동기로 실행하는데, 세 변수를 개발자는 다 기억해야하고 세 변수에 대한 로딩, 성공, 실패처리를 모두 해야한다.
Copied!
이때promise.all처럼 useQuery를 하나로 묶을 수 있는데, 그것이useQueries입니다.promise.all과 마찬가지로 하나의 배열에 각 쿼리에 대한 상태 값이 객체로 들어옵니다.
일부 삽화의 내용은 직접 번역하여 새로 첨부했습니다. 가독성에 문제가 있다면 피드백 부탁드립니다.
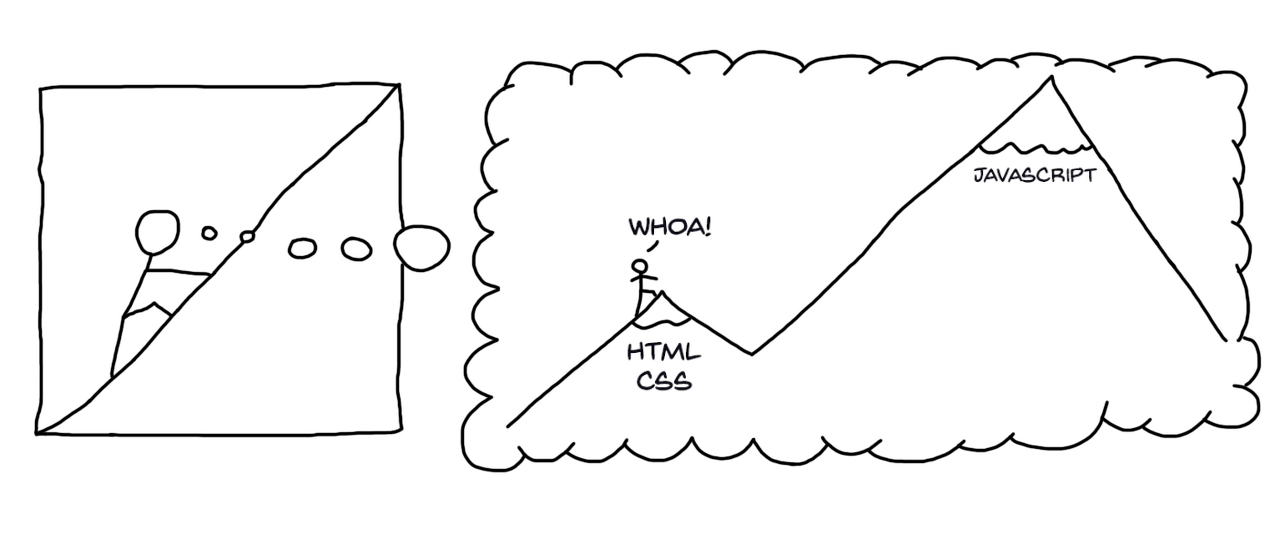
여러분이 처음 프론트엔드 개발을 배우고 나서 스타일이나 그리드 시스템 등 미적인 부분에만 집중을 하다가 비지니스 로직, 프레임워크 등을 공부하면서 본격적으로 자바스크립트 코드를 작성하기 시작할 때를 떠올려 보겠습니다.
[처음 시작은 이렇지만..]
이 시점에서 단순히 jQuery 트릭을 조금 쓰거나 시각적 효과 일부를 JS 로 구현하는 정도를 벗어나게 됩니다. 단순히 웹페이지가 아니라웹 애플리케이션을 만들기 위한 큰 그림을 그리게 되죠.
JS 코드를 작성하는데 많은 노력을 들이면서 상호작용, 세부 시스템이나 로직을 생각하기 시작하겠죠. 앱이 잘 동작하기 시작하면서 살아움직이는 듯한 기분이 듭니다. 완전히 새롭고 신나는 세계가 펼쳐집니다. 하지만 그러면서 새로운 문제를 마주하게 됩니다.
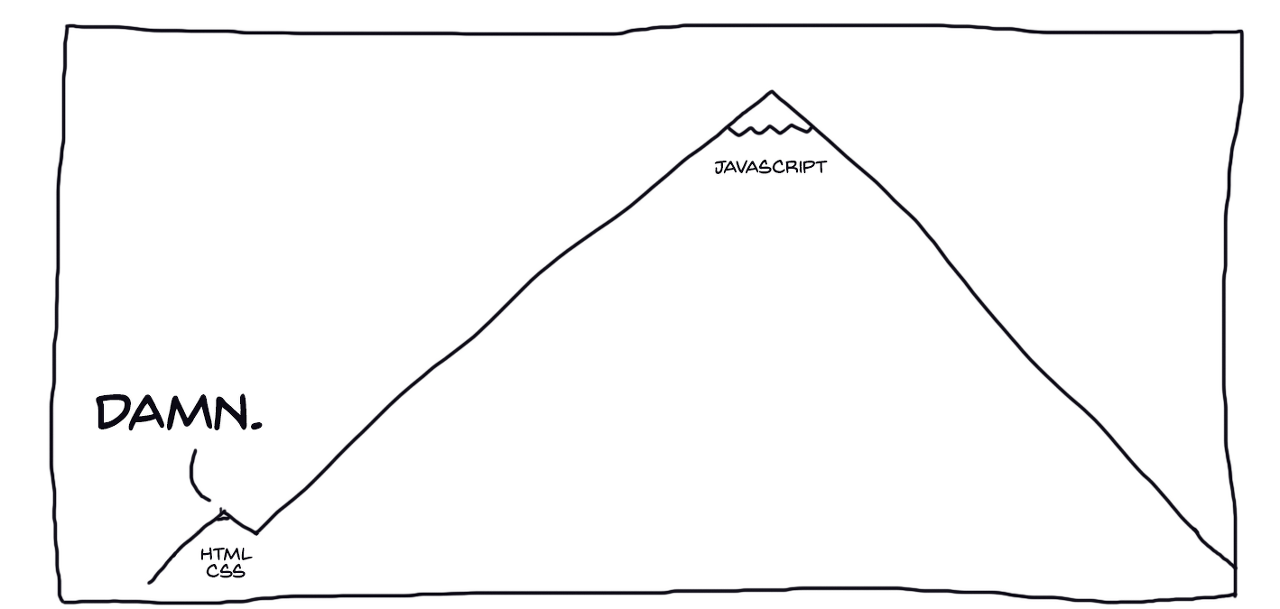
[…결국은 이렇게 끝이 납니다. 그리고 끝이 없어요!]
하지만 여러분은 실망하지 않습니다. 새로운 아이디어는 계속 떠오르고, 더욱 많은 코드를 작성합니다. 블로그 포스트에서 본 다양한 기술이나 방법론을 적용하고, 문제 해결을 위한 온갖 접근법들을 (어설프게나마) 주물럭거려봅니다.
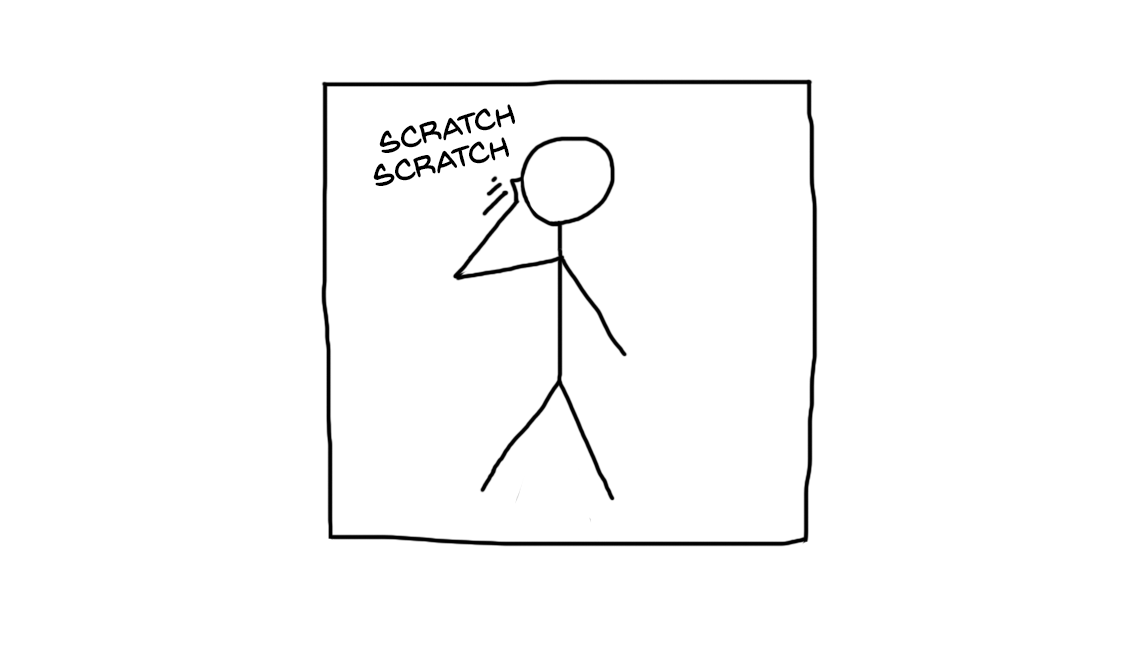
그러다 갑자기 가려운 기분을 느끼기 시작합니다.
처음 작성한script.js파일이 커지면서 한 시간 전에는 200 줄 정도였던 코드가 이제 500 줄이 넘어가기 시작했습니다. “흠, 별 문제는 아냐” 라고 생각합니다. 깔끔하고 유지보수가 용이한 코드에 대한 글을 읽어봤으니, 문제를 해결하기 위해 로직이나 블록, 컴포넌트별로 파일을 분리하기 시작합니다. 다시 그럴싸한 모양새의 프로젝트가 되었습니다. 모든 것은 꼼꼼하게 정리된 라이브러리처럼 보입니다. 여러 파일이적절하게 이름이 붙어있고 적절한 디렉토리에 있기 때문입니다.
코드는 모듈화하고 유지보수하기 좋게 되었는데도 갑자기 또 가려운 기분이 들기 시작합니다. 하지만 이번에는 뭐가 문제인지 잘 파악이 안됩니다.
웹 애플리케이션(웹 앱)은 선형적으로 동작하는 일이 거의 없습니다. 사실 어떤 웹 앱이든 많은 액션은 갑자기 (때로는 기대하지 않았을 때나 자발적으로) 발생합니다.
앱은 네트워크 이벤트, 사용자의 조작, 타이밍이 설정된 동작 등 여러 종류의 비동기적인 동작에 적절하게 응답해야 합니다. 그렇게 갑자기 “비동기” 와 “경합 상태” 라 불리는 괴물들이 문을 두드립니다.
멋지게 모듈화된 코드가 비동기 코드라는 못난 배우자와 짝을 맺어야하는 상황이 되었습니다. 이제 가려운 기분이 어디서 오는지 명확해졌습니다.“대체 이놈의 비동기 코드를 어느 부분에 두어야 하지?”라고 어려운 질문이 고개를 들기 시작합니다.
지금 앱은 아름답게 블록 단위로 구성되어 있을 겁니다. 페이지 이동 및 컨텐츠를 구성하는 컴포넌트는 적절한 디렉토리에 깔끔하게 놓일 수 있고, 자그마한 헬퍼 스크립트 파일들은 코드를 반복해서 쓰지 않고 자잘한 일들을 처리할 수 있습니다. 모든 것은app.js라는 하나의 엔트리 파일로 관리되고 구동됩니다. 깔끔하죠.
하지만 여러분의 목표는 비동기 코드를앱의 한 부분에서 실행하여 처리하고 다른 부분으로 보내는 것입니다.
비동기 코드가 UI 컴포넌트 안에 있어야 할까요? 아니면 메인 파일에? 앱의 어떤 부분에서 반응(reaction)을 다루는 책임을 가지고 있어야 할까요? 데이터 처리는? 에러 처리는? 마음속에서 다양한 접근 방식을 시도해보지만 불편한 기분은 가시지 않습니다. 앱을 더 확장하고 싶어도 쉽지 않으리라는 사실도 알고 알고 있습니다. 가려운 기분은 여전히 사라지지 않았고, 더 이상적이고 다양한 상황에 대응 가능한 해답이 필요해졌습니다.
안심하세요. 여러분이 뭘 잘못한 것은 아닙니다. 사실 더 구조화될수록 생각을 할 수록 가려운 기분은 더욱 심해지게 됩니다.
이제 위의 문제를 해결하기 위한 글을 찾아서 읽어보거나 이미 준비된 솔루션들을 찾아보게 됩니다. 처음에는 프라미스(Promise)가 콜백보다 낫다는 글을 보게 되고, 그 다음에는 RxJS 가 무엇인지 이해하려고 머리를 싸매게 됩니다(그리고 인터넷의 어떤 사람이 “RxJS 는 인류가 웹 개발을 하는데 있어 정당한 구원자” 라고 주장하는 이유를 찾기도 합니다). 더 많은 글을 읽다 보니 왜 어떤 사람은redux를redux-thunk없이 쓴다는건 말이 안된다고 이야기하고, 다른 사람은redux-saga를 가지고 똑같은 소리를 하는지 이해하려고 아둥바둥하게 됩니다.
결국에는 혼란스러운 말들만 머리 속에 가득 차서 두통이 생길 지경이 되었습니다. 문제 해결을 위한 방대한 양의 접근 방법 때문에 멘탈은 터져나갈 것 같고요. 왜 이렇게 많은 방법이 있는걸까요? 좀 쉽게 해결할 수 없을까요? 아니면 인터넷에 있는 사람들이 하나의 좋은 패턴을 사용하는 대신에 치고박고 싸우는 것을 좋아하는 걸까요?
이 주제가 사소하지 않기 때문입니다.
어떤 프레임워크를 사용하더라도, 비동기 코드를 적절하게 배치하는 일은 지금도, 앞으로도 결코 간단하지 않을 것입니다. 모든 목적에 부합하는 하나의 완성된 솔루션은 존재하지 않습니다. 요구사항, 환경, 필요로 하는 결과 등 다양한 요소에 크게 달라지기 때문입니다.
그리고 이 글을 통해 모든 문제를 해결하는 완벽한 방법을 제공하는 것도 아닙니다. 하지만 여러분들이 비동기 코드를 조금 더 쉽게 생각할 수 있도록 도움이 되었으면 합니다. 왜냐면 위에 나온 모든 기술들은 아주 간단한 원칙을 기반으로 하고 있기 때문입니다.
공통적인 부분
특정한 관점에서, 프로그래밍 언어들은 구조적으로 복잡하게 되어있지 않습니다. 어쨌든 값을 어딘가에 저장하고if문들이나 함수 호출을 통해 흐름을 제어하여 계산을 처리해주는 단순한 기계들(dumb calculator-like machines)에 불과합니다. 명령형이면서 약간은 객체지향형인 언어(역주: 그리고 함수형)로서 자바스크립트도 저 기계들의 한 종류에 불과합니다.
말인 즉슨 기본적으로 모든 비동기 세계에서 나온 물건들은 (redux-saga 건, RxJS 건, observable 이나 또 다른 변종이던) 반드시 같은 기본 원리에 의존한다는 뜻입니다. 이 라이브러리들의 마법같아 보이는 동작은 실제로 마법이 아닙니다. 그저 잘 알려진 기초 위에 만들어졌으며, 아주 심층적인 부분은 새로 발명된 것이 아닙니다.
이 사실을 아는게 뭐가 그리 중요할까요? 예를 한번 들어보겠습니다.
뭔가 만들어(그리고 부숴)봅시다
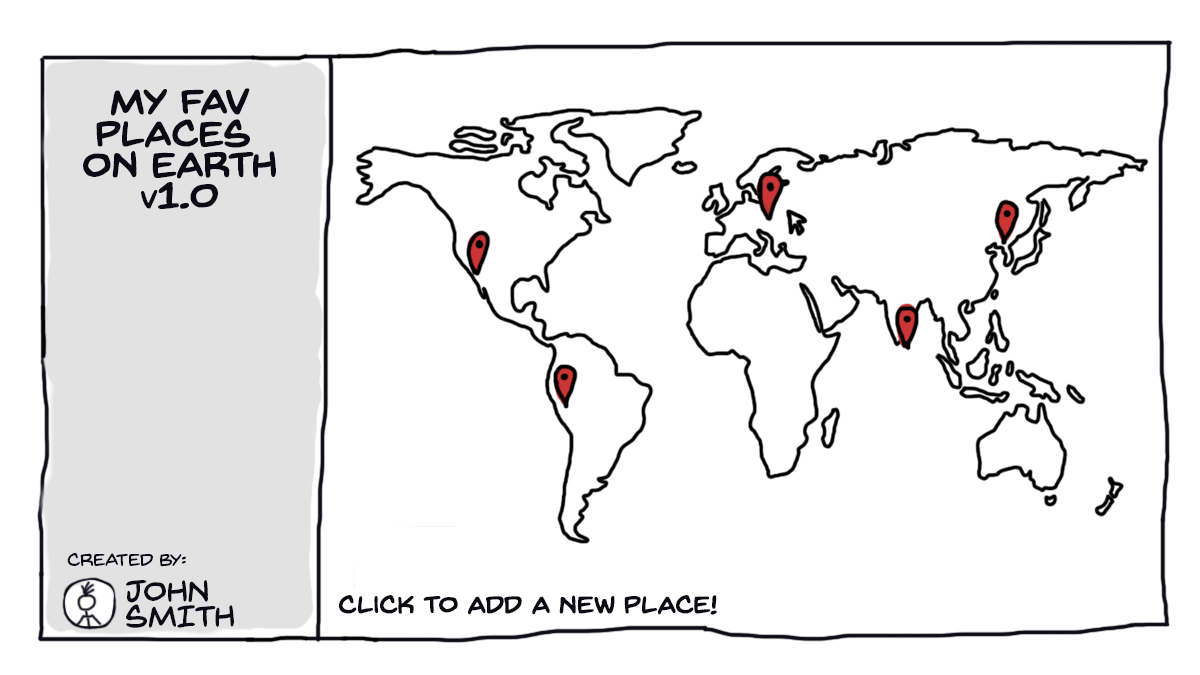
아주 간단한 애플리케이션을 생각해봅시다.아주 간단한걸로요. 예를 들어 지도에 우리가 제일 좋아하는 장소를 표시해 두는 작은 앱이 있습니다. 특별히 대단한 구석은 없어요. 그냥 오른쪽에는 지도가 있고 왼쪽에는 단순히 사이드바가 있는 형태입니다. 지도를 클릭하면 그 위에 새로운 마커가 표시됩니다.
물론 약간 욕심을 가지고 조금 기능을 추가할 예정입니다. 점찍어둔 장소의 리스트를 로컬 스토리지에 저장하려 합니다.
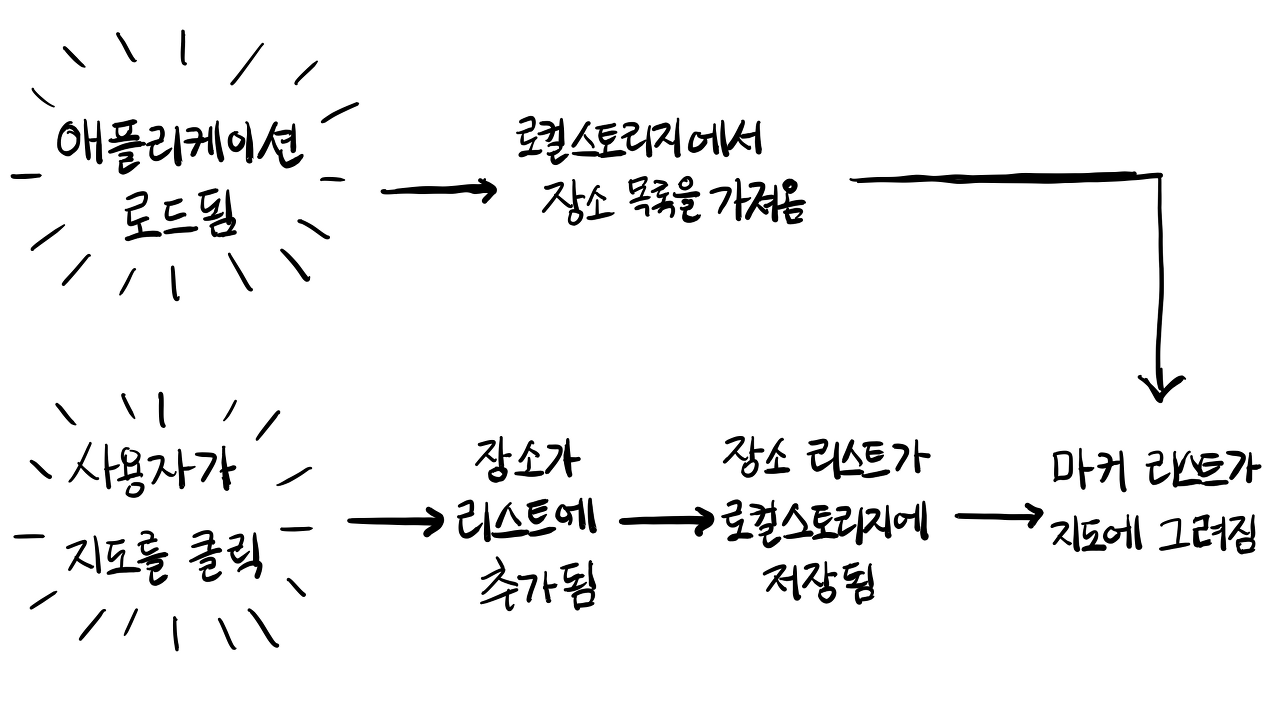
이제 세부 사항을 기반으로 앱의 기본적인 동작 흐름을 차트로 그려보겠습니다.
보시다시피 그리 복잡하진 않을겁니다.
튜토리얼을 간략히 하기 위해 아래의 예는 어떠한 프레임워크나 UI 라이브러리도 사용하지 않을 예정입니다. 그저 바닐라 자바스크립트만 들어있습니다. 그리고 Google Maps API 를 일부 사용합니다. 비슷한 앱을 직접 만들고자 하시면이 링크를 통해API 키를 등록하셔야 합니다.
약간의 스타일을 추가했다고 가정하고 만들었습니다. (스타일은 이번 글에 직접적인 관련은 없으므로 따로 올리지 않겠습니다.) 믿거나 말거나 이 앱은 제대로 동작합니다.
좀 못생겼지만 잘 동작합니다.하지만 확장할 수가 없습니다.아이고야.
먼저, 함수들의 책임이 서로 뒤섞여있습니다.SOLID 원칙에 대해 들어보신 적 있다면, 벌써부터단일 책임 원칙을 위배하고 있다는 것을 이미 파악하셨을 겁니다. 예제 코드 자체는 단순하지만 하나의 코드 파일이 사용자 액션과 데이터 다루기, 그리고 동기화를 모두 담당하고 있습니다. 이렇게 하면 안 됩니다. 왜냐고요?에이, 그래도 잘 동작 하잖아요라고 할 수도 있겠습니다. 하지만 다음에 추가할 기능을 생각해보면 유지보수하기 아주 어려운 형태입니다.
다른 방식으로 설득해보겠습니다. 우리가 앱을 확장하여 아래와 같은 새 기능을 추가한다고 합시다.
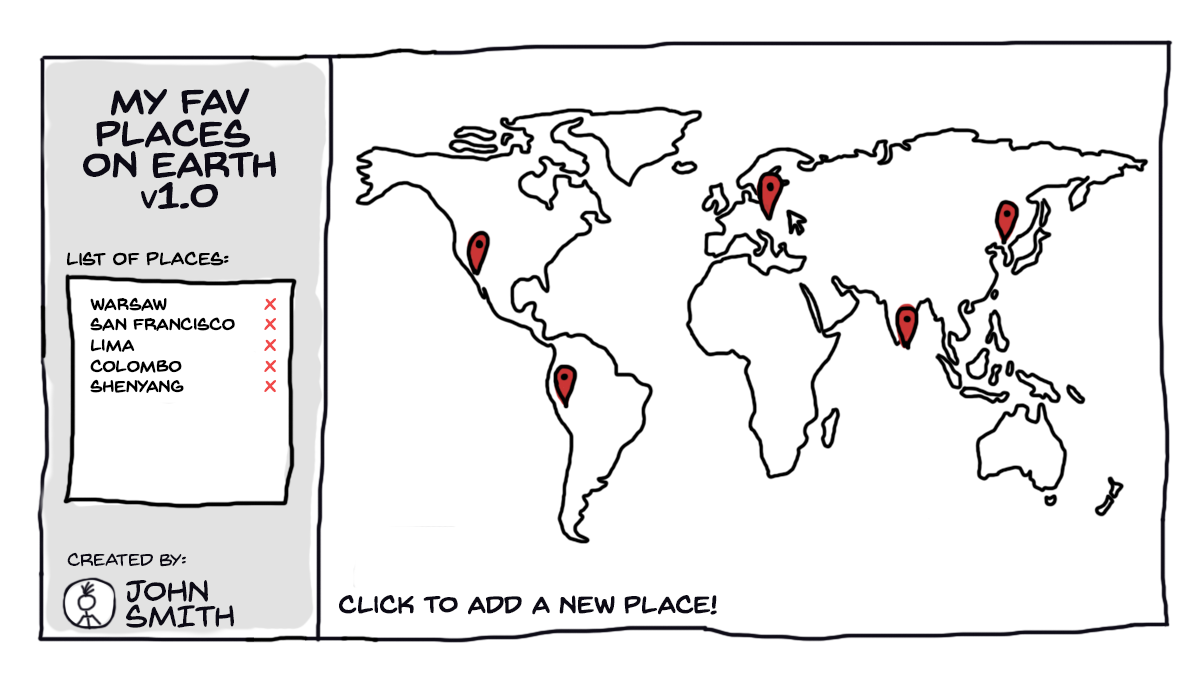
첫 번째로 우리는 사이드바에 표시 된 장소들의 리스트를 놓고, 두 번째로 Google API 를 사용하여 도시 이름을 표시하고 싶습니다. 여기서 비동기 메커니즘(동작 원리, mechanism)이 사용됩니다.
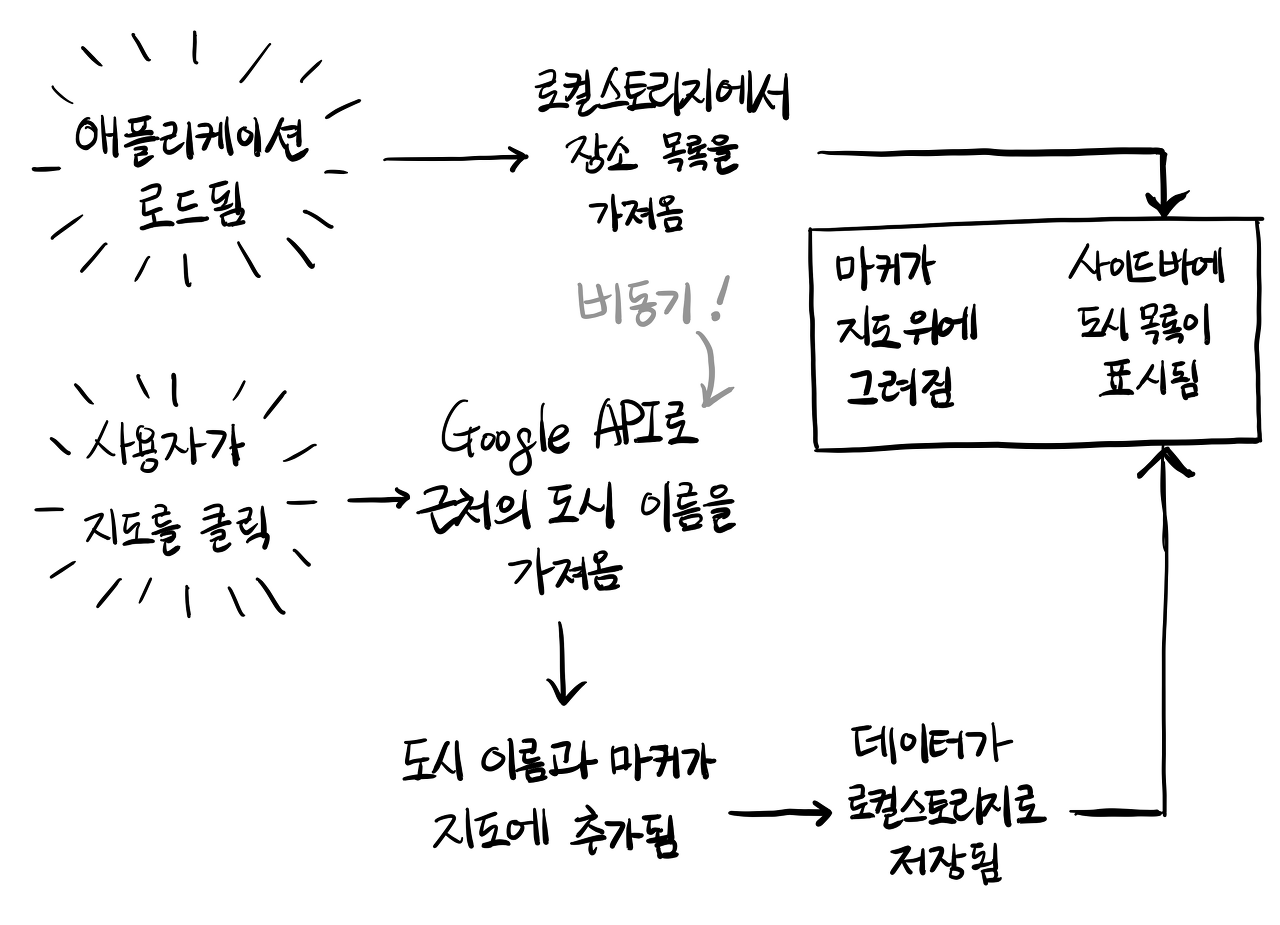
그러면 새로운 플로우차트는 이렇게 됩니다.
[참고: 도시 이름을 찾는 방법은 아주 어려운게 아닙니다. 아주 쉬운 Google Maps API 가 제공됩니다.여기서 확인해보세요!]
Google API 로 도시 이름을 가져올 때 주요한 특징이 있습니다.즉시 가져오는게 아니라는 겁니다.Google 의 자바스크립트 라이브러리에서 적절한 서비스를 호출하면 응답이 돌아올 때까지 약간의 시간이 걸립니다. 덕분에 조금 혼란스럽지만, 배우는데 확실히 도움이 되는 문제가 나타났습니다.
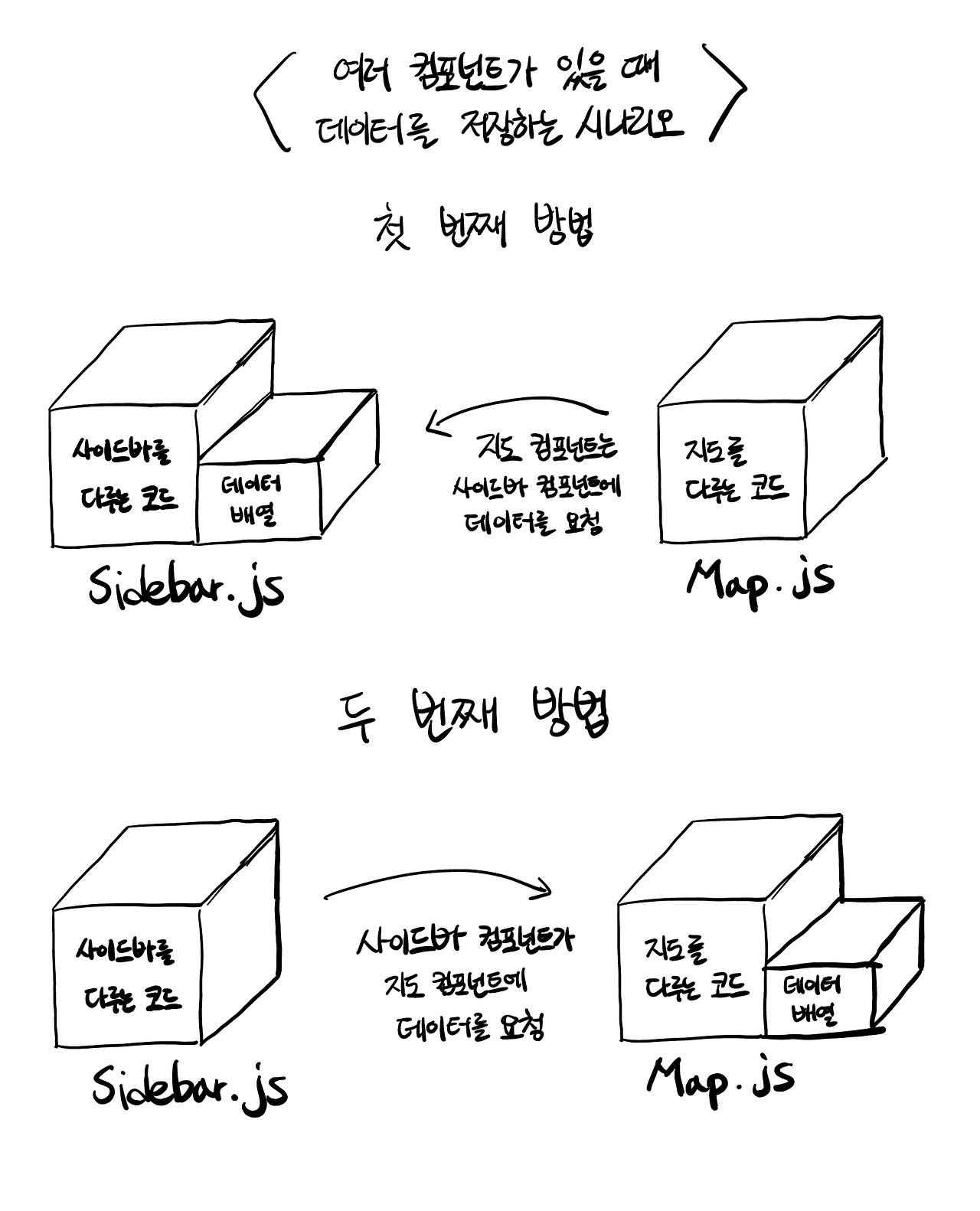
UI 이야기로 돌아가서 확실히 보이는 문제를 하나 짚어보겠습니다. 보기에는 두 개로 나뉜 인터페이스 영역이 있습니다. 사이드바와 메인 컨텐츠 영역입니다. 절대로 둘을 한꺼번에 다루는거대한 코드 덩어리 하나만 작성하면 안됩니다.이유는 명백합니다. 만약 시간이 조금 흘러 네 개의 컴포넌트를 만들어야 한다면? 아니면 여섯 개? 백 개가 된다면? 그러므로 코드를 조각조각 나누어야 합니다. 아래의 방식으로 자바스크립트 파일을 두 개로 나눌 것입니다. 하나는 사이드바를 담당하고, 다른 하나는 지도 부분을 담당합니다. 그런데 어떤 파일이 지역을 담아놓는 배열을 다루어야 할까요?
어떤 접근 방식이 더 옳을까요? 첫 번째일까요, 두 번째일까요? 사실 답은둘 다 아닙니다.단일 책임 원칙 기억나시죠? 깔끔하고 모듈화된 (그리고 멋진) 코드를 유지하기 위해서 어딘가 다른 곳에 관심사(concerns)를 분리하고 데이터 로직을 두어야 합니다. 이렇게요.
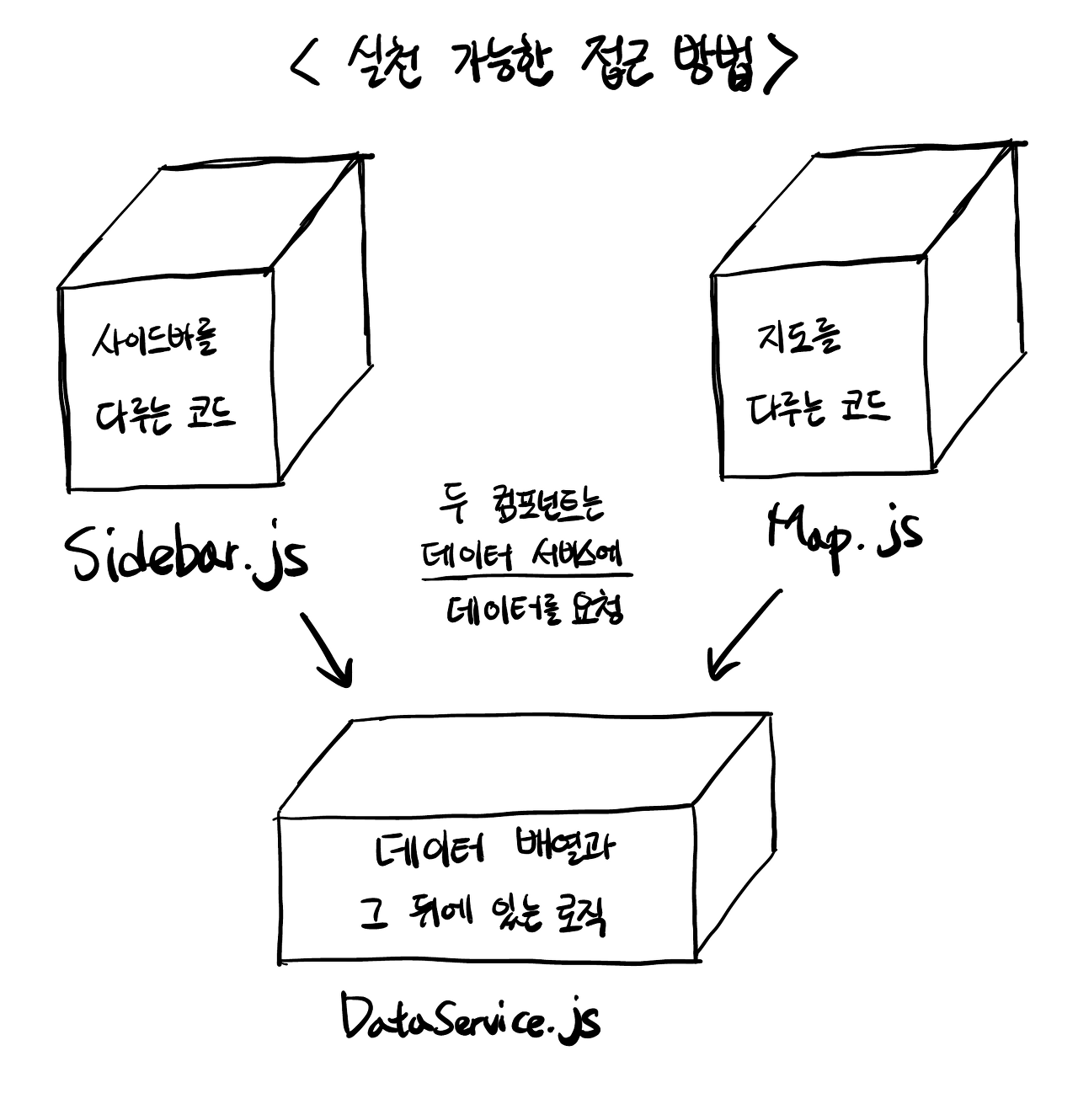
코드 분리의 성배(Holy grail)가 완성되었습니다.(역주: 원글 작성자가 성배라는 표현을 사용한 것은 아마이 용어 사용에서 따온 것과 유사하다고 생각합니다)데이터를 저장하고 다루는 로직을 다른 파일로 옮길 수 있게 되었습니다. 이 서비스 파일은 로컬 스토리지와 동기화를 하는 등의 매커니즘과 관심사를 다루는 책임을 가지게 됩니다. 그 반대로 컴포넌트들은 오로지 인터페이스 부분만 담당하게 됩니다. 말 그대로 단단한 구조(SOLID)를 이루었네요. 이제 설명한 패턴을 코드에 적용해보겠습니다.
데이터 서비스 파일
/* dataService.js */let myPlaces = [];const geocoder = new google.maps.Geocoder();export function addPlace(latLng) { // Google API 를 실행하여 도시 이름을 검색한다. // 두 번째 인자는 요청한 결과에 따른 응답이 왔을 때 처리를 담당하는 콜백 함수 geocoder.geocode({ location: latLng }, function(results) { try { // 콜백 안에서 결과에 따른 도시 이름을 추출한다 const cityName = results .find(result => result.types.includes('locality')) .address_components[0] .long_name; // 그리고 우리가 준비해놓은 변수에 집어넣는다 myPlaces.push({ position: latLng, name: cityName }); // 그 다음 localStorage와 동기화한다 localStorage.setItem('myPlaces', JSON.stringify(myPlaces)); } catch (e) { // 도시를 찾을 수 없을 때 콘솔에 메세지를 출력한다 console.error('No city found in this location! :('); } });}// 현재 가지고 있는 장소의 목록을 출력export function getPlaces() { return myPlaces;}// localStorage에 있는 정보를 꺼내 콜렉션에 넣는 함수function initLocalStorage() { const placesFromLocalStorage = JSON.parse(localStorage.getItem('myPlaces')); if (Array.isArray(placesFromLocalStorage)) { myPlaces = placesFromLocalStorage; publish(); // 지금은 만들어지지 않은 함수. 나중에 적용될 예정 }}initLocalStorage();
/* sidebar.js */import { getPlaces } from './dataService.js';function renderCities() { // 도시 목록을 표현하기 위한 DOM 엘리먼트를 가져온다 const cityListElement = document.getElementById('citiesList'); // 먼저 클리어 하고 cityListElement.innerHTML = ''; // forEach 함수를 써서 하나씩 다시 리스트를 그려낸다. getPlaces().forEach(place => { const cityElement = document.createElement('div'); cityElement.innerText = place.name; cityListElement.appendChild(cityElement); });}renderCities();
이제 우리를 가렵게 만들었던 큰 부분은 사라졌습니다. 코드는 다시 깔끔하게 알맞은 위치에 놓였습니다. 하지만 무작정 기뻐하지 말고 코드를 한번 실행시켜 봅시다.
…이런 어떤 액션을 실행해도 인터페이스가 반응하지 않네요.
왜 그럴까요? 음, 아직 동기화에 관련된 어떤 것도 구현하지 않았습니다. 불러온 함수를 사용하여 장소를 추가하고 장소가 추가되었다는 신호를 어디에도 보내지 않았습니다. 또한addPlaces()함수를 실행하고 바로 뒤에getPlaces()함수를 실행하도록 하지도 않았습니다. 왜냐면 도시 이름을 찾는 기능은 비동기적으로 동작하여 약간 시간이 걸리기 때문입니다.
뭔가 뒤에서 돌아가는데 인터페이스는 그 결과를 모르고 있습니다. 마커는 지도에 추가되더라도 사이드바에는 어떠한 변화도 일어나지 않고 있습니다. 어떻게 이 문제를 해결해야 할까요?
아주 간단한 방법은 주기적으로 서비스에 자료를 요청하는(poll) 겁니다. 예를 들어 모든 컴포넌트가 서비스로부터 매 초마다 자료를 가져오도록 만들 수도 있겠지요. 이렇게요.
어떻게든 작동은 하겠지만 최선의 방법일까요? 전혀 그렇지 않죠. 대부분의 경우 특별한 영향을 주지도 않는 액션으로 앱의 이벤트 루프를 가득 채우고 있습니다.
보통 여러분은 우편물이나 택배가 도착했는지 확인하려고 매 시간마다 우체국에 들르지 않습니다. 비슷하게 자동차 수리를 맡겨놓았다면 정비공에게 매 30 분마다 수리가 완료되었는지 전화를 하지도 않습니다. (최소한 여러분이 그런 사람이 아니길 바랍니다) 대신 전화가 오는 것을 기다립니다. 부탁한 일이 마무리되었을 때 정비공은 어떻게 우리에게 전화를 할 수 있을까요? 당연하게도 정비공에게 우리의 전화번호를 남겨 놓았기 때문입니다.
이제 “우리의 전화번호를 남겨 둔다” 는 비유를 자바스크립트 안에서 실현해보겠습니다.
자바스크립트는 굉장히 근사한 언어입니다. 한 가지 독특한 특징은 함수를 여느 다른 값들과 같이 취급한다는 것입니다. 전문적인 표현으로 “함수는일급 객체(first-class citizens)이다” 라고 합니다. 어떠한 함수도 변수에 할당할 수 있고, 다른 함수의 인자로 넘길 수 있다는 뜻입니다. 이미 이런 동작방식을 알고 있으리라 생각합니다.setTimeout,setInterval같은 함수 혹은 다양한 이벤트 리스너가 콜백을 받는 것을 기억하시나요? 그런 방식이 함수를 인자로 사용하는 대표적인 예입니다.
이 특징이 바로 비동기 시나리오 처리의 기본이 됩니다.
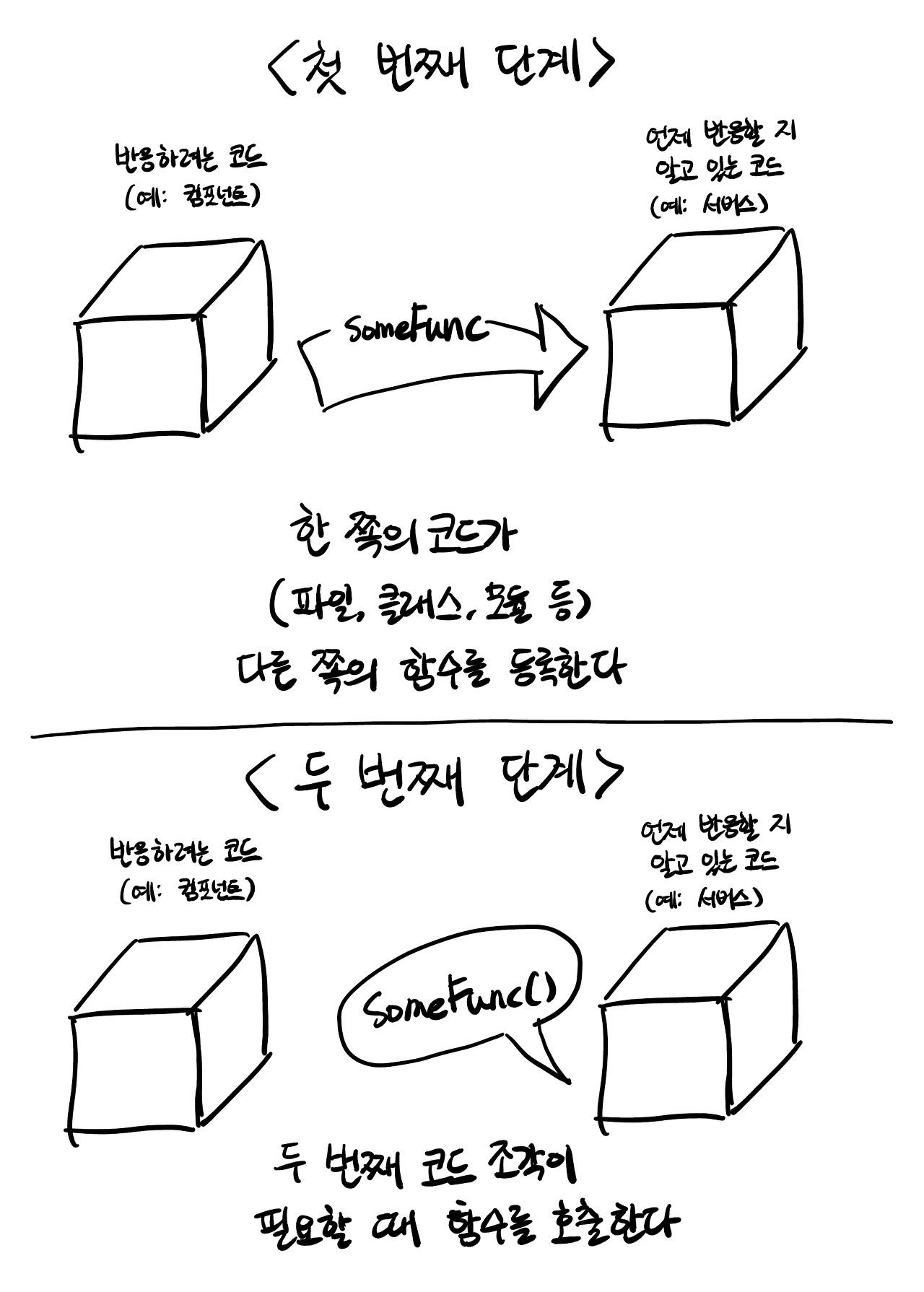
UI 를 업데이트하는 함수를 정의하고 완전히 다른 부분으로 전달한 뒤에 호출되도록 만들 수 있는겁니다.
이 매커니즘을 사용하여renderCities함수를dataService어딘가로 전달할 수 있습니다. 그리고 필요할 때 실행되도록 만들면 되는거죠. 어쨌든 서비스는 언제 데이터가 컴포넌트로 전달되어야 할지 정확히 알고 있으니까요.
까짓거 한 번 해보죠! 서비스 쪽에 함수를 기억할 수 있는 공간을 마련해두고 특정한 시점에 실행되도록 만들어보겠습니다.
/* dataService.js */// ...let changeListener = null;export function subscribe(callbackFunction) { changeListener = callbackFunction;}export function addPlace(latLng) { geocoder.geocode({ location: latLng }, function(results) { try { const cityName = results .find(result => result.types.includes('locality')) .address_components[0] .long_name; myPlaces.push({ position: latLng, name: cityName }); // 추가된 부분 if (changeListener) { changeListener(); } localStorage.setItem('myPlaces', JSON.stringify(myPlaces)); } catch (e) { console.error('No city found in this location! :('); } });}// ...
그리고 사이드바쪽 코드에 추가합니다.
/* sidebar.js */import { getPlaces, subscribe } from './dataService';// ...renderCities();subscribe(renderCities);
어떻게 동작하는지 보이시나요? 사이드바를 다루는 코드가 실행되면서renderCities함수를dataService안에 등록했습니다.
그리고dataService는 실행 될 필요가 있을 때 실행됩니다. 이 경우에는데이터가 변경되었을 때(addPlaces()함수가 호출되면서) 실행됩니다.
정확히 말씀드리면, 코드의 한 부분은 이벤트의수신자(SUBSCRIBER, 여기서는 사이드바 컴포넌트)가 되고, 다른 한 부분은발행자(PUBLISHER, 서비스 메서드)가 됩니다. 짠짜짠, 우리는 발행-구독 패턴(publish-subscribe pattern)의 가장 기본적인 형태를 구현했습니다. 이 패턴이 거의 모든 고급 비동기 처리 방식의 기본 개념이 되지요.
더 살펴볼 게 있을까요?
지금 구현된 코드로는 오로지 하나의 컴포넌트만 데이터 처리 결과를 수신할 수 있습니다. (다른 말로는 하나의 수신자만 있다는 뜻입니다) 만약 다른 함수를subscribe()함수에 넘기게 되면 현재 설정된changeListener를 덮어쓰게 됩니다. 이 문제를 해결하기 위해 배열로 바꾸어서 함수를 받도록 처리하겠습니다.
/* sidebar.js */import { getPlaces, subscribe } from './dataService';function renderCities(placesArray) { const cityListElement = document.getElementById('citiesList'); cityListElement.innerHTML = ''; // getPlaces 함수 호출을 placesArray로 교체 placesArray.forEach(place => { const cityElement = document.createElement('div'); cityElement.innerText = place.name; cityListElement.appendChild(cityElement); });}// 초기 값으로 getPlaces() 전달renderCities(getPlaces());subscribe(renderCities);
이렇게 다양한 활용 방법이 있습니다. 다른 액션을 처리하기 위해 새로운 주제(혹은 채널)을 만들 수도 있습니다. 마찬가지로publish와subscribe함수를 전혀 다른 코드 파일로 분리하여 활용할 수도 있습니다. 하지만 지금 단계에선 그렇게 하지 않아도 충분합니다. 아래의 영상은 여태 작성한 예제로 만들어진 앱을 시연하는 영상입니다.
여태까지 살펴 본 발행-구독 패턴이 원래 알고 있던 듯한 기분이 들지 않나요? 조금 더 생각을 해 보면 여태 사용해왔던element.addEventListener(action, callback)의 형태와 상당히 유사한 작동 원리를 가지고 있습니다. 특정 이벤트에 어떤 함수를구독하도록만들고, DOM 요소에 의해 액션이발행되면그 함수가 호출되는 거죠. 똑같네요.
제목을 되짚어보면,왜 이 패턴이 오지게(bloody) 중요한걸까요?장기적으로 바라보면 바닐라 자바스크립트를 고수하면서 수동으로 DOM 을 수정하는 일은 거의 의미가 없습니다. 이벤트를 전달하고 수신하는데 수동으로 제어하는 매커니즘과 유사하죠. 다양한 프레임워크들은 이미 사용하고 있는 솔루션이 있습니다. 앵귤러는 RxJS 를 사용하고, 리액트는 state-props 기반으로 하며 Redux 를 사용하여 이 구조를 강화할 수도 있고요. 말 그대로 쓸만한 모든 라이브러리나 프레임워크들이 각자의 데이터 동기화 방법을 가지고 있습니다.
솔직히 이야기하자면위의 모든 것들이 발행-수신 패턴(Pub-Sub Pattern)의 다양한 변종을 사용하고 있습니다.
이미 이야기했듯이 DOM 이벤트 리스너는 UI 액션을발행하고구독하는정도에 불과합니다. 조금 더 나아가서Promise는 뭘까요? 특정 관점에서 바라보면 단순히 우리가 미뤄둔 어떠한 액션이 완료되는 것을구독할 수 있게 하고, 데이터가 준비되면발행하는것입니다.
리액트의 state 와 props 가 변경되는 것은 어떨까요? 컴포넌트들이 업데이트 되는 원리는 데이터 변화를구독하는것입니다. 웹소켓의on()은요? Fetch API 는? 특정한 네트워크 액션을구독하는것이죠. 리덕스? 이건 스토어의 변화를구독하도록하죠. 그렇다면 RxJS 는? 말 할 것도 없이 하나의 거대한구독패턴입니다.
모두 같은 원리를 가지고 있습니다. 그 뒤에 마법의 유니콘같은게 숨어있는 것도 아니고요. 뻔한 시트콤 엔딩이나 마찬가집니다(역주: ending of the Scooby-Doo episode 라는 표현이 사용되었지만 맥락 상 뻔하다는 표현에 중점을 두었습니다).
대단한 발견은 아니지만 꼭 알아두면 좋습니다.
어떠한 비동기 처리 방법을 사용하든지, 언제나 같은 패턴의 변종일 뿐입니다. 무언가는 구독을 하고, 무언가는 발행을 하는거죠.
그렇기 때문에 이 개념이 필수요소라고 말씀드리는 겁니다. 언제나 발행과 구독에 대해 생각할 수 있습니다. 마음에 새겨두고 다양하게 학습해보세요. 다양한 비동기 처리 방법으로 더 크고 복잡한 애플리케이션을 만들어 보세요. 아무리 어려워 보일지라도 발행자와 구독자로 모든 것을 동기화하도록 노력해보세요.
여전히 이번 글에서 다루지 못한 몇 가지 주제들이 있습니다.
리스너가 더 이상 필요하지 않을 때 구독을 해지(unsubscribe)하는 방법
다양한 주제(Multi-topic)를 구독하는 방법 (addEventListener로 다른 이벤트에 구독을 수행하는 것 처럼)
확장된 아이디어: 이벤트 버스 등
이번에 배운 지식을 확장하기 위해서 Pub-Sub 패턴을 구현한 몇 가지 자바스크립트 라이브러리를 살펴보실 수 있습니다.
계속 실험해보고 건드려보세요. 다양한 용어들에 겁 먹지 마세요. 어렵게 포장된 보통의 코드인 경우가 많습니다.
계속 생각하세요. 그럼 이만!
번역 후기
내용이 무척 길어서 쉽사리 접근할 엄두를 내지 못했지만 마치고 나니 뿌듯하네요. 정말 중요한 개념이라고 생각하며 내용을 살펴보았고, 많은 분들에게 도움이 될 수 있으리라 생각하여 망설이지 않고 번역 작업을 진행했습니다. 삽화가 다양하게 들어있어서, 이해를 돕고자 삽화의 내용도 직접 다시 그려봤는데 글씨를 더 잘 쓰지 못해 조금 아쉬웠네요.
참고로 디자인 패턴에 대해 조금이라도 들어 보신 분들은 옵저버 패턴(Observer Pattern)에 대해 들어보셨을 겁니다. 그 패턴과 Pub-Sub 가 어떻게 다른가? 라고 궁금해하실 수도 있으리라 생각해서 아래의 첨부자료를 남깁니다.
npm 에서 시작한 node package management의 역사는, 이제 3가지 옵션이 주어져 있다. yarn 1.0 (이제 yarn classic 이라고 부르겠다) 과 yarn 2.0 (yarn berry) 두 가지 버전도 사뭇 다른 점이 많다는 것을 감안한다면, 이제 크게 4가지 선택지가 존재 한다고 볼 수 있다.
그리고 위 3가지 패키지 관리자들은 아래와 같은 기본적인 기능 (node 모듈을 설치하고, 관리하는 등)을 제공하고 있다.
metadata 작성 및 관리
모든 dependencies 일괄 설치 또는 업데이트
dependencies 추가, 업데이트, 삭제
스크립트 실행
패키지 퍼블리쉬
보안 검사
따라서 설치 속도나 디스크 사용량, 또는 기존 워크 플로우 등과 어떻게 매칭 시킬지와 같은 기능 외적인 요구 사항에 따라 패키지 관리자를 선택하는 시대가 도래했다고 볼 수 있다.
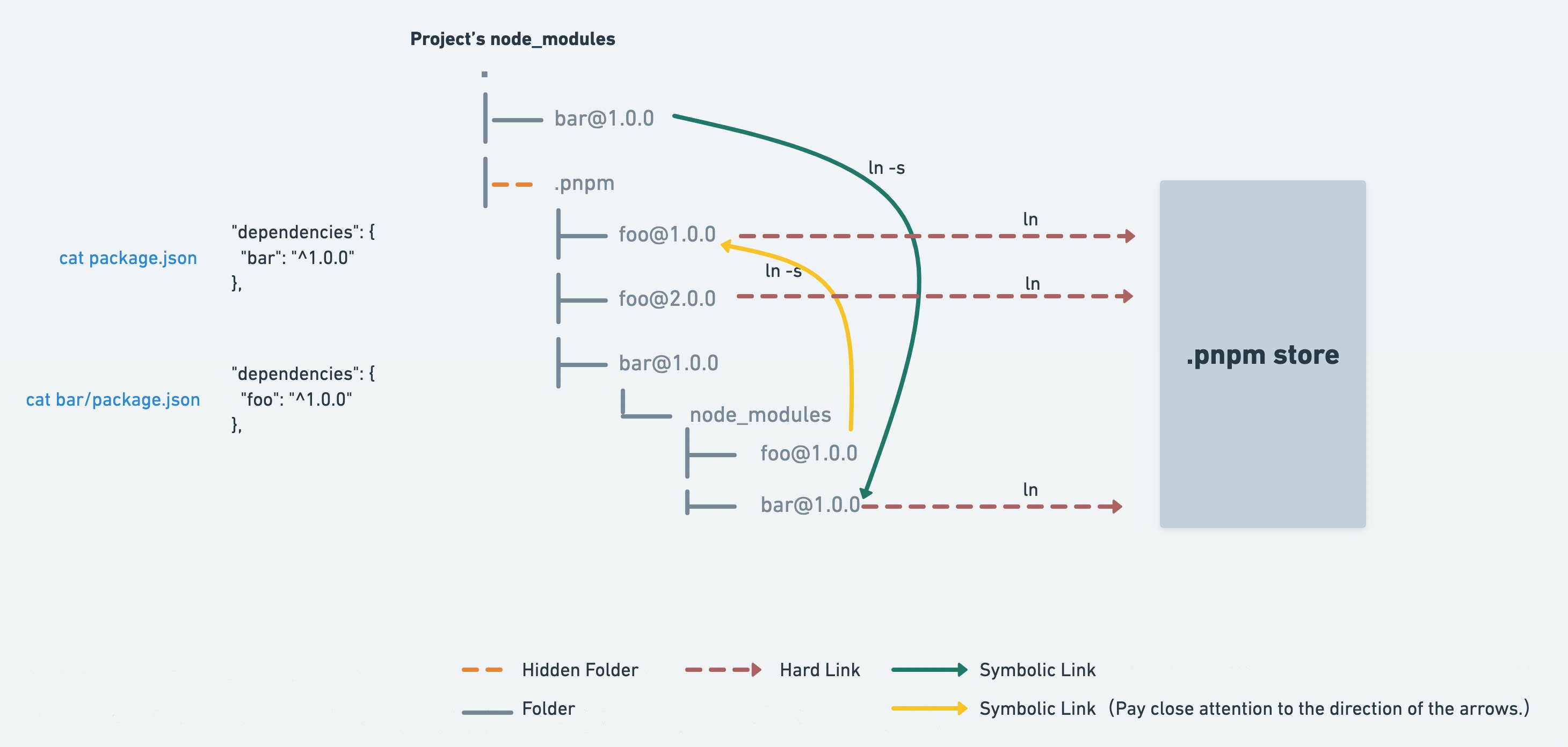
겉으로는 기능적으로 비슷해보이고 무엇을 선택하든 별 차이는 없어보이지만, 패키지 관리자들의 내부 동작은 매우 다르다. npm 과 yarn의 경우 flat 한 node_modules 폴더에 dependencies 를 설치했다. 그러나 이러한 전략은 비판에서 자유롭지 못하다. (어떤 문제인지는 뒤에서 설명하도록 한다.)
그래서 등장한 pnpm은 이러한 dependencies를 중첩된 node_modules 폴더에 효율적으로 저장하기 시작했고, yarn berry는 plug and play (pnp) 모드를 도입하여 이러한 문제를 해결하기 시작했다.
pnpm 홈페이지에 있는 yarn과 npm을 쓰레기통에 쳐박은 이미지가 매우 인상적이다. 🤔 vue가 react를 쓰레기통에 쳐박는 이미지를 달아놨다면...
자바스크립트 패키지 관리자의 역사
모두가 잘 알고 있는 것 처럼 최초의 패키지 매니저는 2010년 1월에 나온 npm 이다. npm 은 패키지 매니저가 어떤 동작을 해야하는 지에 대한 핵심적인 개념을 잡았다고 볼 수 있다.
10여년이 넘는 시간 동안 npm 이 존재했는데, yarn, pnpm 등이 등장하게 된 것일까?
node_modules효율화를 위한 다른 구조 (nested vs flat, node_modules, vs pnp mode)
보안에 영향을 미치는 호이스팅 지원
성능에 영향을 미칠 수 있는lock파일 형식
디스크 효율성에 영향을 미치는 패키지를 디스크에 저장하는 방식
대규모 모노레포의 유지 보수성 과 속도에 영향을 미치는 workspace라 알려진 멀티 패키지 관리 및 지원
새로운 도구와 명령어 관리에 대한 관리
이와 관련된 다양하고 확장가능한 플러그인과 커뮤니티 툴
다양한 기능 구현 가능성과 유연함
npm 이 최초로 등장하 이래로 이러한 니즈가 어떻게 나타났는지, yarn classic은 그 이후 등장해서 어떻게 해결했는지, pnpm이 이러한 개념을 어떻게 확장했는지, yarn berry가 전통적인 개념과 프로테스에 의해 설정된 틀을 깨기 위해 어떠한 노력을 했는지 간략한 역사를 파악해보자.
선구자 npm
본격적으로 시작하기에 앞서 재밌는 사실을 이야기 해보자면,npm은node package manager의 약자가 아니다. npm의 전신은 사실pm이라 불리는 bash 유틸리티인데, 이는pkgmakeinst의 약자다. 그리고 이의 node 버전이npm인 것이다.
npm 이전에는 프로젝트의 dependencies를 수동으로 다운로드하고 관리하였기 때문에 엄청난 혁명을 가져왔다고 볼 수 있다. 이와 더불어 메타데이터를 가지고 있는package.json와 같은 개념, dependencies를node_modules라 불리는 폴더에 설치한다는 개념, 커스텀 스크립트, public & private 패키지 레지스트리와 같은 개념들 모두 npm에 의해 도입되었다.
많은 혁명을 가져온 yarn classic
2016년의 블로그 글에서, 페이스북은 구글과 몇몇 다른 개발자들과 함께 npm이 가지고 있던 일관성, 보안, 성능 문제 등을 해결하기 위한 새로운 패키지 매니저를 만들기 위한 시도를 진행 중이라고 발표 했다. 그리고 이듬해Yet Another Resource Negotiator의 약자인 yarn을 발표했다.
yarn은 대부분의 개념과 프로세스에 npm을 기반으로 설계했지만, 이외에 패키지 관리자 환경에 큰 영향을 미쳤다. npm과 대조적으로, yarn은 초기버전의 npm의 주요 문제점 중 하나였던 설치 프로세스의 속도를 높이기 위해 작업을 병렬화 하였다.
yarn은 dx(개발자 경험), 보안 및 성능에 대한 기준을 높였으며, 다음과 같은 개념을 패키지 매니저에 도입하였다.
native 모노레포 지원
cache-aware 설치
오프라인 캐싱
lock files
yarn classic은 2020년 부터 유지보수 모드로 전환되었다. 그리고 1.x 버전은 모두 레거시로 간주하고 yarn classic으로 이름이 바뀌었다. 현재는 yarn berry에서 개발과 개선이 이루어지고 있다.
pnpm 빠르고 효율적인 디스크 관리
pnpm은 2017년에 만들어졌으며, npm 의 drop-in replacement(설정을 바꿀 필요 없이 바로 사용가능하며, 속도와 안정성 등 다양한 기능 향상이 이루어지는 대체품) 으로, npm만 있다면 바로 사용할 수 있다.
pnpm 제작자들이 생각한 npm 과 yarn의 가장 큰 문제는 프로젝트 간에 사용되는 dependencies의 중복 저장이다. yarn classic이 물론 npm 보다 빠르지만, 두 매니저 모두 node_modules 내부에 flat하게 패키지를 설치하여 (=동일한 디렉토리에 flat하게 저장) 관리했다.
pnpm은 이러한 호이스트 방식 대신, 다른 dependencies를 해결하는 전략인content-addressable storage를 사용했다. 이 방법을 사용하면, home 폴더의 글로벌 저장소 (~/.pnpm-store)에 패키지를 저장하는 중첩된 node_modules 폴더가 생성된다. 따라서 모든 버전의 dependencies은 해당 폴더에 물리적으로 한번만 저장되므로, single source of truth를 구성하고, 상당한 디스크 공간을 절약할 수 있다.
이는 node_modules의 레이아웃을 통해 이루어지고,symlinks를 사용하여 dependencies의 중첩된 구조를 생성한다. 여기서 폴더 내부의 모든 패키지 파일은 저장소에 대한 하드 링크로 구성되어 있다.
yarn berry 는 2020년 1월에 출시되었으며 yarn classic의 업그레이드 버전이다. yarn 팀은 본질적으로 새로운 코드 베이스와 새로운 원칙을 가진 완전히 새로운 패키지 매니저라는 것을 분명하게 하기 위해yarn berry라고 부르기 시작했다.
yarn berry에서 눈여겨 봐야 할 것은plug n play로,node_modules를 fix 위한 전략이다. node_modules를 생성하는 대신,.pnp.cjs라 불리는 의존성 lookup 파일이 생성되는데, 이는 중첩된 폴더 구조 대신 단일 파일 이기 때문에 더 효율적으로 처리할 수 있다. 또한 모든 패키지는.yarn/cache폴더 내부에 zip 파일로 저장되므로, node_modules 폴더보다 더 디스크 공간을 적게 차지한다.
yarn berry 팀은 이후 릴리즈에서 많은 문제를 해결하고자 노력했다. PnP의 비호환성을 해결하기 위해 default 작동 모드를 쉽게 바꾸기 위한 몇가지 방법을 제안했다.node_modules plugin의 도움으로, 기본적인 node_modules로 돌아가는 데 한 줄의 코드만으로 가능해졌다.
호환성 표에서 볼 수 있듯이, 많은 대형 프로젝트 들이 점차 yarn berry를 지원하는 방향으로 가기 시작했다.
앞선 3가지 패키지 매니저 중에서 가장 최근에 나왔지만, 패키니 매니저 환경에 많은 영향을 미쳤다. 2020년말, pnpm도 plug n play 방식을 지원하기 시작했다.
패키지 매니저 설치하기
패키지 매니저를 사용하기 위해서는, 개발자의 로컬 혹은 CI/CD 시스템에 설치해야 한다.
npm
nodejs 내부에 npm이 내장되어 있으므로, 추가적으로 작업을 할 필요가 없다.nvm이나volta를 사용하면, node와 npm 버전을 관리하는데 매우 유용하게 쓸 수 있다.
Corepack의 도움으로 node는 yarn classic, yarn berry, pnpm의 바이너리를 shim으로 가지고 있기 때문에 npm의 대체 패키지 매니저를 별도로 설치할 필요는 없다. 이 shim을 활용하면, yarn과 pnpm 명령어를 명시적으로 설피할 필요 없이, 실행할 수 잇다.
Corepack은 nodejs@16.9.0 부터 사전 설치되며, 이전 버전에서는npm install -g corepack으로 설치할 수 있다.
프로젝트의 구조를 살펴보면, 각 패키지 매니저의 주요 특성을 한눈에 살펴볼 수 있다. 특정 패키지 매니저를 구성하는데 사용하는 파일과, 설치단계에서 생성되는 파일을 쉽게 알아볼 수 있다.
기본적으로, 모든 패키지 매니저는 모든 중요한 메타 정보를package.json에 저장한다. 또한 루트 레벨에 설정파일을 사용하여 프라이빗 레지스트리나 dependency resolution 방법을 설정할 수 있다. 그리고 이 단계에서 dependencies를 파일 구조 (node_modules)에 저장하고 lock 파일이 생성된다.
이 글에서는 workspaces에 대해서는 다루지 않는다.
npm
$npm install또는$npm i명령어를 실행하면,package-lock.json이 생성되고node_modules폴더도 생성된다. 이 외에도.npmrc설정 파일도 생성될 수 있다.
$yarn을 실행하면,yarn.lock과node_modules폴더가 생성된다. 마찬가지로.yarnrc파일도 옵셔널로 생성할 수 있다. 이에 더해.npmrc파일이 있으면 이를 이용할 수도 있다. 그리고 캐시 폴더인.yarn/cache/와 현재 yarn classic의 버전을 저장하는.yarn/releases/도 생성될 수 있다. 이처럼 설정에 따라서 다양하게 변경될 수 있다.
install mode에 관계 없이, yarn berry 프로젝트에서는 다른 패키지 관리자보다 더 많은 파일 보다 폴더를 처리해야 한다. 일부는 선택사항이고, 그리고 일부는 필수 사항이다.
yarn berry는 더이상.npmrc다.yarnrc를 사용하지 않는다. 대신yarnrc.yml설정 파일을 필요로 한다. 전통적인node_modules를 생성하는 워크플로우가 존재하는 경우,nodeLinker config파일을 아래와 같은 형태로 제공해야 한다.
# .yarnrc.yml
nodeLinker: node-modules # or pnpm
$ yarn을 실행하면, 모든 의존성을node_modules에 설치한다.yarn.lock파일이 생성되는데, 이 파일은 기존yarn classic과 호환되지는 않는다. 또한 오프라인 모드에서 설치를 위해.yarn/cache폴더도 생성된다.releases폴더는 프로젝트에서 사용하는 yarn berry의 버전을 저장하기 위해 옵셔널로 생성된다.
PnP 모드에는strict와loose모드가 있는데, 일단은 모드에 상관없이yarn을 실행하면.yarn/cache와.yarn/unplugged,.pnp.cjsyarn.lock파일이 생성된다. strict 모드는 기본 값이고, loose는 아래 처럼 옵셔널로 설정해두어야 한다.
pnpm도 다른 패키지 매니저와 마찬가지로package.json이 필요하다.$ pnpm i를 실행하면,node_modules가 생성되는 것 까지는 다른 패키지 관리자와 동일하지만, 앞서 언급한content-addressable storage approach라는 특성 때문에 이후의 구조가 완전히 다르다.
pnpm은 자체 lock 파일인pnp-lock.yml을 생성한다. 그리고 마찬가지로.npmrc로 설정을 추가할 수도 있다.
Lock 파일과 dependency 저장
앞서 언급한 것 처럼, 모든 패키지 매니저는 각자 다른 형태의 lock 파일이 존재한다.
일단 lock 파일의 정의를 먼저 살펴보면, lock 파일이란 매 설치시 결정적이고 (= 항상 같은 버전을 설치하고) 예측가능한 특성을 보장하기 위하여, 각 버전의 정확한 의존성 버전을 저장하고 있는 파일을 의미한다.package.json은 정확한 버전이 기재되어 있는 것이 아니고,>= 1.2.5와 같은 형식의버전 범위 aka 시멘틱 버저닝이 존재하기 때문에, lock파일이 없다면 매 설치마다 설치하는 버전이 달라질 수 있다.
lock 파일은 또한 체크섬이 존재하는데, 이에 대해서는 보안 관련 섹션에서 다룬다.
이 lock 파일은 npm@5 부터 (package-lock.json), pnpm은pnpm-lock.yaml, yarn은yarn.lock형태로 존재한다.
이전 섹션에서 언급했던 것처럼, 전통적인 접근 방식으로는 모든 의존성을node_modules을 설치하는 방법을 npm, yarn classic, pnpm(의 경우엔 구조가 조금 다르다) 사용하는 것을 볼 수 있다.
yarn berry의 PnP 모드에서는 조금 다른 모습을 볼 수 있다.node_modules대신, 모든 의존성을zip파일로 압축하여.yarn/cache와.pnp.cjs형태로 관리한다.
모두 잘알고 있는 것처럼, 모든 팀원이 (모든 머신에서) 같은 버전을 설치하는 것을 보장하기 위해 lock 파일은 버전 컨트롤 내부에 포함시키는 것이 좋다.
CLI commands
cli 커맨드는 워낙 많고 다양하여, 여기에서 모든 것을 다루지는 않으려고 한다. 아래 내용은 개발과정에서 자주 쓰일 수 있는 커맨드를 모아 둔 것이다.
의존성 관리
npmyarn classicyarn berrypnpm
install deps
npm install
yarn installoryarn
like classic
pnpm install
update deps
npm update
yarn upgrade
yarn semver up
pnpm update
update deps to latest
N/A
yarn upgrade --latest
yarn up
pnpm update --latest
update deps interactively
N/A
yarn upgrade-interactive
like classic
pnpm up -- interactive
add specific dep
npm i react
yarn add react
like classic
pnpm add react
add specific dep in dev
npm i -D babel
yarn add -D babel
like Classic
pnpm add -D babel
uninstall deps
npm uninstall react
yarn remove react
like Classic
pnpm remove react
uninstall deps without updatepackage.json
npm uninstall --no-save
N/A
N/A
N/A
패키지 관련
아래 예제는ntl과 같은 바이너리 파일 처럼, development 환경에서 유틸리티 도구를 구성하는 패키지를 관리하는 명령어를 나타낸다.
yarn berry에서는 보안상의 이유로 패키지에서 지정한 바이너리 또는package.json에 명시된 실행할 수 있다는 것을 염두해 두어야 한다. 이는pnpm에서도 마찬가지다.
npmyarn classicyarn berrypnpm
install, update, remove package globally
npm i -g ntl
yarn global ad ntl
N/A
pnpm add --global ntl
run binaries from terminal
npm exec ntl
yarn ntl
yarn ntl
pnpm ntl
run binaries from script
ntl
ntl
ntl
ntl
dynamic package execution
npx ntl
N/A
yarn dlx ntl
pnpm dlx ntl
자주 쓰이는 커맨드
npmyarn classicyarn berrypnpm
publish
npm publish
yarn publish
yarn npm publish
pnpm publish
list installed deps
npm ls
yarn list
like Classic
pnpm list
list outdated deps
npm outdated
yarn outdated
yarn upgrade-interactive
pnpm outdated
print info about deps
npm explain ntl
yarn why ntl
like Classic
pnpm why ntl
init project
npm init
yarn init
yarn init
pnpm init
성능과 디스크 관리의 효율성
성능은 의사결정을 하는데 있어 중요한 부분이다. 이 섹션에서는 각 프로젝트의 벤치 마크 성능을 다룬다.
pnpm 또한 체크섬을 활용하여 패키지의 무결성을 확인한다. pnpm은npm과 yarn classic에서 이슈가 되는 패키지 호이스팅을 하지 않기 때문에 이러한 문제를 피한다. 이 대신, 위험한 dependency 액세스의 위험성을 제거하는 내부에 중첩된node_modules폴더를 생성한다. 즉, dependency가 package.json 에서 명시적으로 선언된 경우에만 다른 dependency에 액세스 할 수 있다.
결론
현재 대부분의 패키지 매니저들은 모두 사용하기에 무리가 없는 수준까지 기능이 구성되어 있다. 대부분의 패키지 매니저가 기능성 사이에서 동등함을 보이고 있다. 물론, 그 아래에서 동작하는 방식은 매우 다르다.
pnpm은 npm과 비슷해보이지만, 종속성 관리 측면에서 매우 다른 모습을 보인다. pnpm을 사용하면 성능이 향상되고, 디스크 효율성을 극대화 할 수 있다. yarn classic도 훌륭한 선택지이지만, 레거시로 간주되고 가까운 미래에 지원이 중단될 수도 있는 가능성이 존재해서 선택하는 것을 추천하지는 않는다. yarn berry의 plug n play 는 완전히 새로운 혁신으로 다가왔지만, 아직 그 모든 잠재력을 달성한 것 같지는 않다. 그럼에도 요즘 사람들이 많이 쓰는 패키지 매니저는 yarn berry의 pnp 인 것으로 보인다. 성능과 디스크 효율성, 속도 모두에서 뛰어난 모습을 보이고 있다.
이것 저것 생각하기 쉽지 않고, 또 빠르고 쉽게 접근하고 싶다면 npm을 쓰는 것도 나쁘지 않다. 물론 다른 패키지 매니저에 비해서 성능이나 속도면에서 뒤쳐지는 감이 있지만, 긴 역사를 기반으로 한 많은 문서와 시행착오를 확인할 수 있는 다양한 글들은, 초보자들이 접근하기에는 가장 용이한 선택지가 될 것이다.